好好学习,天天向上
常规
SimpleRev
题目内容
校验字符串
通过拼接操作形成长度128字节的Key
程序根据用户输入变形一个Table
将key与变形后的一个Table对比
若一致则成功
key1="ADSFK";
key3="kills";
something[0]=0x776F646168LL; //'wodah'
something[1]=0LL;join函数

没啥特别的
就是拼接
key3+something
注意something需要倒序(小端存储)
text=”killshadow”
key处理
key=”ADSFKNDCLS”
经过一波小写转换操作

key=adsfkndcls”
处理之后v3=0x0a
Table生成
key=adsfkndcls”
input = “a”
while ( 1 )
{
input = getchar();
if ( input == 10 )
break;
if ( input == 32 )
{
++spaceOrder; // spaceNum
}
else
{
if ( input <= 96 || input > 122 )
{
if ( input > 64 && input <= 90 ) // 大写字母
{
Table[spaceOrder] = (input - 39 - key[v3 % v5] + 97) % 26 + 97;
++v3;
}
}
else // 小写字母
{
Table[spaceOrder] = (input - 39 - key[v3 % v5] + 97) % 26 + 97;
++v3;
}
if ( !(v3 % v5) )
putchar(32);
++spaceOrder;
}
}最后比较Table与Text
text="killshadow"
char Table[104]我的尝试
看了下算法大致是通过输入大写字母来生成text
于是通过逆向还原一下 通过最后将计算结果放大到大写字母的范围内
# Table[spaceOrder] = (input - 39 - key[v3 % key_len] + 97) % 26 + 97;
def fangda(a):
while 1:
if 65 <= a <=90:
break
if a > 122:
a -= 26
elif a < 65:
a += 26
return a
if __name__ == '__main__':
mylist = {}
key = 'adsfkndcls'
final = "killshadow"
for i in range(0,10):
temp = ord(final[i]) - 97
temp -= 97
temp += 39
temp += ord(key[i])
temp = fangda(temp)
mylist[i] = chr(temp)
for i in range(10):
print(mylist[i], end='')别人的解法
非常简短
key = 'adsfkndcls'
text = 'killshadow'
v5 = len(text)
flag = ''
for i in range(len(text)):
for j in range(65,91): #仅遍历大写字母
if ord(text[i]) == (j - 39 - ord(key[i % v5]) + 97) % 26 + 97:
flag += chr(j)
print(flag)可以看到思路是直接进行爆破
利用了密码本的特性
直接遍历大写字母生成Table值来和text比较
如果符合则加入
Luck_guy
Linux64位程序
题目结构
主函数
int __cdecl main(int argc, const char **argv, const char **envp)
{
welcome(argc, argv, envp);
puts("_________________");
puts("try to patch me and find flag");
puts("please input a lucky number");
__isoc99_scanf("%d");
patch_me(0);
puts("OK,see you again");
return 0;
}patch_me函数
int __fastcall patch_me(int a1)
{
int result; // eax
if ( a1 % 2 == 1 )
result = puts("just finished");
else
result = get_flag();
return result;
}get_flag()函数
case3可以看到小彩蛋
unsigned __int64 get_flag()
{
unsigned int v0; // eax
int i; // [rsp+4h] [rbp-3Ch]
int j; // [rsp+8h] [rbp-38h]
__int64 s; // [rsp+10h] [rbp-30h] BYREF
char v5; // [rsp+18h] [rbp-28h]
unsigned __int64 v6; // [rsp+38h] [rbp-8h]
v6 = __readfsqword(0x28u);
v0 = time(0LL);
srand(v0);
for ( i = 0; i <= 4; ++i )
{
switch ( rand() % 200 )
{
case 1:
puts("OK, it's flag:");
memset(&s, 0, 0x28uLL);
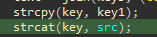
strcat((char *)&s, f1);
strcat((char *)&s, &f2);
printf("%s", (const char *)&s);
break;
case 2:
printf("Solar not like you");
break;
case 3:
printf("Solar want a girlfriend");
break;
case 4:
s = 0x7F666F6067756369LL;
v5 = 0;
strcat(&f2, (const char *)&s);
break;
case 5:
for ( j = 0; j <= 7; ++j )
{
if ( j % 2 == 1 )
*(&f2 + j) -= 2;
else
--*(&f2 + j);
}
break;
default:
puts("emmm,you can't find flag 23333");
break;
}
}
return __readfsqword(0x28u) ^ v6;
}patch_me()处理
可以看到patch_me函数按照正常逻辑无法进入get_flag函数

于是在鼠标指向的条件判断出patch一下,将jnz改为jmp指令
再次反汇编可以看到能顺利执行get_flag函数了
unsigned __int64 __fastcall patch_me(int a1)
{
return get_flag();
}get_flag()处理
关键逻辑如下
v0 = time(0LL);
srand(v0);
for ( i = 0; i <= 4; ++i )
{
switch ( rand() % 200 )
{
case 1:
puts("OK, it's flag:");
memset(&s, 0, 0x28uLL);
strcat((char *)&s, f1);
strcat((char *)&s, &f2);
printf("%s", (const char *)&s);
break;
case 2:
printf("Solar not like you");
break;
case 3:
printf("Solar want a girlfriend");
break;
case 4:
s = '\x7Ffo`guci';
v5 = 0;
strcat(&f2, (const char *)&s);
break;
case 5:
for ( j = 0; j <= 7; ++j )
{
if ( j % 2 == 1 )
*(&f2 + j) -= 2;
else
--*(&f2 + j);
}
break;
default:
puts("emmm,you can't find flag 23333");
break;
}
}case1是打印flag的关键
f1已知:f1 = “GXY{do_not_”
f2未知,需要由case4和case5生成
case4应该是单次将字符串拷贝到f2
case则是对字符串进行解密,执行次数未知
可以看到生成随机数只会有5次
那么这里直接考虑静态用算法爆破
将字符串s按照case5的算法解密,直到输出的字符串像flag了就可以拼接起来。
解密脚本
经过测试刚好只需要执行一次case5即可
#include <stdio.h>
#include <string.h>
char f2;
int main() {
int j = 0;
__int64 s = 0x7F666F6067756369LL;
strcat(&f2, (const char*)&s);
for (j = 0; j <= 7; ++j)
{
if (j % 2 == 1)
*(&f2 + j) -= 2;
else
--* (&f2 + j);
}
const char* f1 = "GXY{do_not_";
puts("OK, it's flag:");
memset(&s, 0, 0x28uLL);
strcat((char*)&s, f1);
char* temp = (char*)&f2 + 9;
*temp = '\0';
strcat((char*)&s, &f2);
printf("%s", (char*)&s);
}直接抄了伪代码 运行后还触发异常 栈崩溃了哈哈
python为了练习也写了一波 感谢兄弟姐妹的指导
s = '\x7ffo`guci'
s = list(s)
list.reverse(s)
for i in range(8):
if i % 2 == 1:
temp = ord(s[i]) - 2
s[i] = chr(temp)
else:
temp = ord(s[i]) - 1
s[i] = chr(temp)
s1 = 'flag{do_not_'
print(s1 + ''.join(str(i) for i in s))动态解法
上面都把patch_me处理了,不动态解一波题说不过去啊。
用IDA远程调试程序
根据上面分析需要分别执行case4,case5,case1。
我采用的方法是修改rand函数产生的随机值,令其满足跳转条件。
所以可以选择在0x400829处下断点
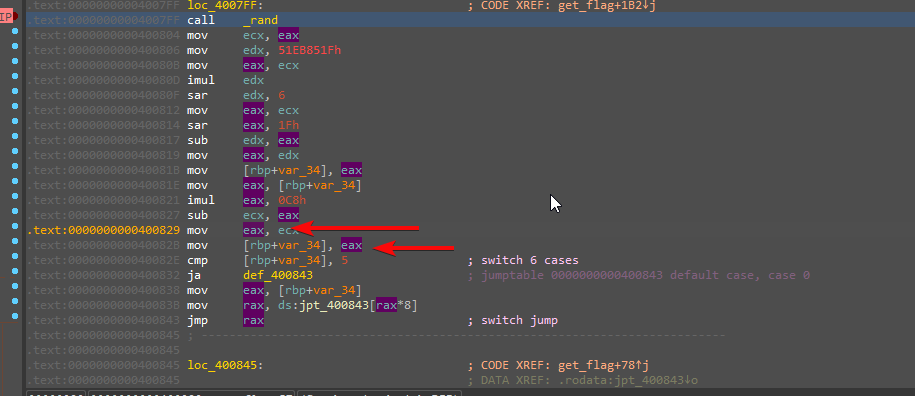
如图在执行到400829时,我会将RAX的值依次改为4,5,1

最后直接获取Flag
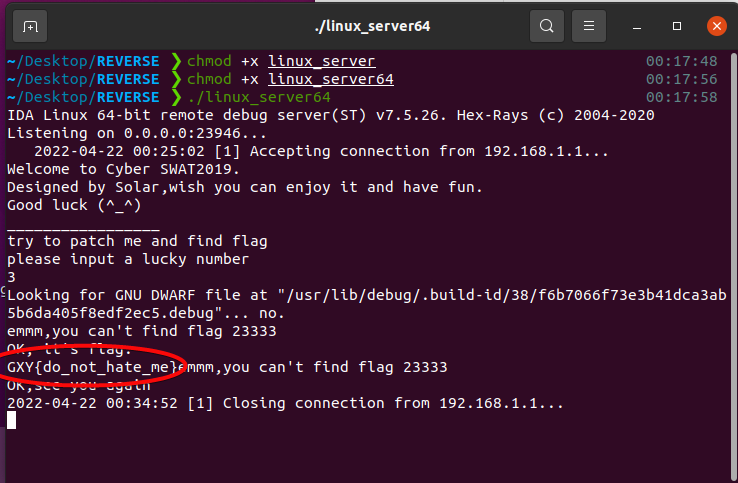
因为一共生成5次随机数 所以有2次不用管
不影响看Flag
刮开有奖
整体逻辑
题目要求输入长度为8
memset(input, 0, 0xFFFFu);
GetDlgItemTextA(hDlg, 1000, input, 0xFFFF);
if ( strlen(input) == 8 )
{
Table[0] = 'Z';
Table[1] = 'J';
Table[2] = 'S';
Table[3] = 'E';
Table[4] = 'C';
Table[5] = 'a';
Table[6] = 'N';
Table[7] = 'H';
Table[8] = '3';
Table[9] = 'n';
Table[10] = 'g';
sub_4010F0(Table, 0, 10);
memset(v9, 0, 0xFFFFu);
v9[0] = input[5];
v9[2] = input[7];
v9[1] = input[6];
check1 = (const char *)sub_401000(v9, strlen(v9));
memset(v9, 0, 0xFFFFu);
v9[1] = input[3];
v9[0] = input[2];
v9[2] = input[4];
check2 = (const char *)sub_401000(v9, strlen(v9));
if ( input[0] == Table[0] + 34
&& input[1] == Table[4]
&& 4 * input[2] - 141 == 3 * Table[2]
&& input[3] / 4 == 2 * (Table[7] / 9)
&& !strcmp(check1, "ak1w")
&& !strcmp(check2, "V1Ax") )
{
MessageBoxA(hDlg, "U g3t 1T!", "@_@", 0);
}逻辑如下
- 通过
sub_4010F0初始化Table - 输入的第678个字符通过
sub_401000生成校验值check1 - 输入的第345个字符通过
sub_401000生成校验值check2 - 用初始化完毕的Table验证输入的1234位
sub_4010F0
sub_4010F0
Table[0] = 'Z';
Table[1] = 'J';
Table[2] = 'S';
Table[3] = 'E';
Table[4] = 'C';
Table[5] = 'a';
Table[6] = 'N';
Table[7] = 'H';
Table[8] = '3';
Table[9] = 'n';
Table[10] = 'g';
sub_4010F0(Table, 0, 10);
int __cdecl sub_4010F0(int a1, int a2, int a3)
{
int result; // eax
int i; // esi
int v5; // ecx
int v6; // edx
result = a3;
for ( i = a2; i <= a3; a2 = i )
{
v5 = 4 * i;
v6 = *(_DWORD *)(4 * i + a1);
if ( a2 < result && i < result )
{
do
{
if ( v6 > *(_DWORD *)(a1 + 4 * result) )
{
if ( i >= result )
break;
++i;
*(_DWORD *)(v5 + a1) = *(_DWORD *)(a1 + 4 * result);
if ( i >= result )
break;
while ( *(_DWORD *)(a1 + 4 * i) <= v6 )
{
if ( ++i >= result )
goto LABEL_13;
}
if ( i >= result )
break;
v5 = 4 * i;
*(_DWORD *)(a1 + 4 * result) = *(_DWORD *)(4 * i + a1);
}
--result;
}
while ( i < result );
}
LABEL_13:
*(_DWORD *)(a1 + 4 * result) = v6;
sub_4010F0(a1, a2, i - 1);
result = a3;
++i;
}
return result;
}大概是排序将Table从小到大排序
经过调试验证一下 Table的值分布如下
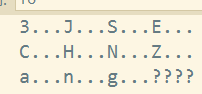
可见确实是排序
Table = ‘3JSECHNZang’
上面调试没跑完 后面重新跑了一下代码才对
#include <stdio.h>
#include <Windows.h>
#define _DWORD DWORD
int __cdecl sub_4010F0(int Table, int arg_0, int arg_10)
{
int result; // eax
int i; // esi
int v5; // ecx
int v6; // edx
result = arg_10;
for ( i = arg_0; i <= arg_10; arg_0 = i )
{
v5 = 4 * i;
v6 = *(_DWORD *)(4 * i + Table);
if ( arg_0 < result && i < result )
{
do
{
if ( v6 > *(_DWORD *)(Table + 4 * result) )
{
if ( i >= result )
break;
++i;
*(_DWORD *)(v5 + Table) = *(_DWORD *)(Table + 4 * result);// 后面小则覆盖前面的
if ( i >= result )
break;
while ( *(_DWORD *)(Table + 4 * i) <= v6 )
{
if ( ++i >= result )
goto LABEL_13;
}
if ( i >= result )
break;
v5 = 4 * i;
*(_DWORD *)(Table + 4 * result) = *(_DWORD *)(4 * i + Table);
}
--result; // 从后往前找比index_value小的
}
while ( i < result );
}
LABEL_13:
*(_DWORD *)(Table + 4 * result) = v6;
sub_4010F0(Table, arg_0, i - 1);
result = arg_10;
++i;
}
return result;
}
int main(){
int Table[11];
Table[0] = 'Z';
Table[1] = 74;
Table[2] = 83;
Table[3] = 69;
Table[4] = 67;
Table[5] = 97;
Table[6] = 78;
Table[7] = 72;
Table[8] = 51;
Table[9] = 110;
Table[10] = 103;
sub_4010F0(Table, 0, 10);
for(int i = 0; i < 11; i++){
printf("%c",Table[i]);
}
}输出得Table = ‘3CEHJNSZagn’
sub_401000
sub_401000
看起来非常复杂
_BYTE *__cdecl sub_401000(int input, int length)
{
int value_1; // eax
int index1; // esi
size_t value_5; // ebx
_BYTE *buffer1; // eax
_BYTE *v6; // edi
int length_v; // eax
_BYTE *buffer2; // ebx
int temp1; // edi
int i1; // edx
int num3; // edi
int v12; // eax
int i; // esi
_BYTE *result; // eax
_BYTE *v15; // [esp+Ch] [ebp-10h]
_BYTE *buffer3; // [esp+10h] [ebp-Ch]
int v17; // [esp+14h] [ebp-8h]
int index2; // [esp+18h] [ebp-4h]
value_1 = length / 3;
index1 = 0;
if ( length % 3 > 0 )
++value_1;
value_5 = 4 * value_1 + 1;
buffer1 = malloc(value_5);
v6 = buffer1;
v15 = buffer1;
if ( !buffer1 )
exit(0);
memset(buffer1, 0, value_5);
length_v = length;
buffer2 = v6;
buffer3 = v6;
if ( length > 0 )
{
while ( 1 )
{
temp1 = 0;
i1 = 0;
index2 = 0;
do
{
if ( index1 >= length_v )
break;
++i1;
temp1 = *(unsigned __int8 *)(index1 + input) | (temp1 << 8);
++index1;
}
while ( i1 < 3 ); // 执行3次
num3 = temp1 << (8 * (3 - i1));
v12 = 0;
v17 = index1;
for ( i = 18; i > -6; i -= 6 )
{
if ( i1 >= v12 )
{
*((_BYTE *)&index2 + v12) = (num3 >> i) & 0x3F;
buffer2 = buffer3;
}
else
{
*((_BYTE *)&index2 + v12) = 64;
}
*buffer2++ = byte_407830[*((char *)&index2 + v12++)];
buffer3 = buffer2;
}
index1 = v17;
if ( v17 >= length )
break;
length_v = length;
}
v6 = v15;
}
result = v6;
*buffer2 = 0;
return result;
}解读到一半不想看了 去查了下攻略
发现大家先进入byte_407830查看,看到下表。
直接就认作是base64了,学习了。
同时又被提醒了一次 base64编码是每3个字节编码成4个字节

对check1和check2的比对值进行解码
得到Flag的345678位为jMpWP1
再拼接一下前面两位就OK了
解密脚本
比较逻辑
check1 = (const char *)sub_401000(v9, strlen(v9));// check1对应input[5+6+7]
check2 = (const char *)sub_401000(v9, strlen(v9));// check2对应input[2+3+4]
if ( input[0] == Table[0] + 34 // input[0]
&& input[1] == Table[4] // input[1]
&& 4 * input[2] - 141 == 3 * Table[2]
&& input[3] / 4 == 2 * (Table[7] / 9)
&& !strcmp(check1, "ak1w")
&& !strcmp(check2,"V1Ax") )对照比较逻辑写出解密脚本
import base64
if __name__ == '__main__':
flag = ''
Table = '3CEHJNSZagn'
check1 = 'ak1w'
check2 = 'V1Ax'
flag_check1 = str(base64.b64decode(check1),encoding='utf-8')
flag_check2 = str(base64.b64decode(check2),encoding='utf-8')
flag += chr(ord(Table[0]) + 34)
flag += Table[4]
print(flag + flag_check2 + flag_check1)总结:python牛逼
[ACTF新生赛2020]easyre
预先处理
先脱掉UPX壳
查看主函数如下
int __cdecl main(int argc, const char **argv, const char **envp)
{
_BYTE v4[12]; // [esp+12h] [ebp-2Eh] BYREF
_DWORD v5[3]; // [esp+1Eh] [ebp-22h]
_BYTE v6[5]; // [esp+2Ah] [ebp-16h] BYREF
int v7; // [esp+2Fh] [ebp-11h]
int v8; // [esp+33h] [ebp-Dh]
int v9; // [esp+37h] [ebp-9h]
char v10; // [esp+3Bh] [ebp-5h]
int i; // [esp+3Ch] [ebp-4h]
sub_401A10();
qmemcpy(v4, "*F'\"N,\"(I?+@", sizeof(v4));
printf("Please input:");
scanf("%s", v6);
if ( v6[0] != 65 || v6[1] != 67 || v6[2] != 84 || v6[3] != 70 || v6[4] != 123 || v10 != 125 )
return 0;
v5[0] = v7;
v5[1] = v8;
v5[2] = v9;
for ( i = 0; i <= 11; ++i )
{
if ( v4[i] != byte_402000[*((char *)v5 + i) - 1] )
return 0;
}
printf("You are correct!");
return 0;
}注意这里的v10,乍一看不知道哪里改变了它的值。
其实是IDA进行scanf的v6识别是不准确的,被出题人混淆视听了。
需要自己手动改一下局部变量,以后遇到这种情况也可以用类似的方法思考。
分析主函数
更改后再来看主函数逻辑如下
int __cdecl main(int argc, const char **argv, const char **envp)
{
_BYTE v4[12]; // [esp+12h] [ebp-2Eh] BYREF
_DWORD v5[3]; // [esp+1Eh] [ebp-22h]
_BYTE input[18]; // [esp+2Ah] [ebp-16h] BYREF
int i; // [esp+3Ch] [ebp-4h]
sub_401A10();
qmemcpy(v4, "*F'\"N,\"(I?+@", sizeof(v4));
printf("Please input:");
scanf("%s", input);
if ( input[0] != 'A' || input[1] != 'C' || input[2] != 'T' || input[3] != 'F' || input[4] != '{' || input[17] != '}' )
return 0;
v5[0] = *(_DWORD *)&input[5];
v5[1] = *(_DWORD *)&input[9];
v5[2] = *(_DWORD *)&input[13];
for ( i = 0; i <= 11; ++i )
{
if ( v4[i] != byte_402000[*((char *)v5 + i) - 1] )
return 0;
}
printf("You are correct!");
return 0;
}可以看到逻辑是通过输入12位,与byte_402000进行比对。
所以可以写出解密脚本
Dump字符串
需要对byte_402000的内容进行提取,IDA自带的不太好看。

于是我们可以写个简单的python脚本提取一下该区段的内容
import idc
begin = 0x402000
end = 0x40205F
size = end - begin
print(get_bytes(begin,size))直接得到可以复制的字符串带进python,非常方便。

解密脚本
byte_402000 = b'~}|{zyxwvutsrqponmlkjihgfedcba`_^]\\[ZYXWVUTSRQPONMLKJIHGFEDCBA@?>=<;:9876543210/.-,+*)(\'&%$# !"\x00'
def look(a):
for i in range(len(byte_402000)):
if a == chr(byte_402000[i]):
temp = i
return temp;
if __name__ == '__main__':
v4 = "*F'\"N,\"(I?+@"
v5 = ''
for i in range(12):
v5 += chr(look(v4[i]) + 1)
print(v5)这里还遇到一个小坑
注意第4排, byte_402000[i]的类型是int类型,直接和char类型比较是找不到的。
所以一开始函数返回结果类型是nonetype,把我搞懵了好一会儿。
[ACTF新生赛2020]rome
关键逻辑
输入为22位
砍掉ACTF{}的6位还剩16位
被按顺序分配到v1数组中处理
v1[0] = *(_DWORD *)&input[5];
v1[1] = *(_DWORD *)&input[9];
v1[2] = *(_DWORD *)&input[13];
v1[3] = *(_DWORD *)&input[17];
for ( i = 0; i <= 15; ++i )
{
if ( *((char *)v1 + i) > '@' && *((char *)v1 + i) <= 'Z' )
*((_BYTE *)v1 + i) = (*((char *)v1 + i) - 51) % 26 + 65;
if ( *((char *)v1 + i) > '`' && *((char *)v1 + i) <= 'z' )
*((_BYTE *)v1 + i) = (*((char *)v1 + i) - 79) % 26 + 97;
}
for ( i = 0; i <= 15; ++i )
{
result = (unsigned __int8)array[i];
if ( *((_BYTE *)v1 + i) != (_BYTE)result )
return result;
}
result = printf("You are correct!");解密脚本
array = "Qsw3sj_lz4_Ujw@l"
flag = ''
def daxie(a):
while 1:
if a < 'A':
a = chr(ord(a) + 26)
elif a > 'Z':
a = chr(ord(a) - 26)
else:
return a
def xiaoxie(a):
while(1):
if a < 'a':
a = chr(ord(a) + 26)
elif a > 'z':
a = chr(ord(a) - 26)
else:
return a
for i in range(16):
if (array[i] >= 'A') and (array[i] <= 'Z'):
temp = chr(ord(array[i]) - 65)
temp = daxie(chr(ord(temp) + 51))
flag += temp
elif (array[i] >= 'a') and (array[i] <= 'z'):
temp = chr(ord(array[i]) - 97)
temp = xiaoxie(chr(ord(temp) + 79))
flag += temp
else:
flag += array[i]
print(flag)CrackRTF(好评)
主逻辑
int __cdecl main_0(int argc, const char **argv, const char **envp)
{
DWORD length; // eax
DWORD v4; // eax
char Str[260]; // [esp+4Ch] [ebp-310h] BYREF
int v7; // [esp+150h] [ebp-20Ch]
char String1[260]; // [esp+154h] [ebp-208h] BYREF
char Destination[260]; // [esp+258h] [ebp-104h] BYREF
memset(Destination, 0, sizeof(Destination));
memset(String1, 0, sizeof(String1));
v7 = 0;
printf("pls input the first passwd(1): ");
scanf("%s", Destination);
if ( strlen(Destination) != 6 )
{
printf("Must be 6 characters!\n");
ExitProcess(0);
}
v7 = atoi(Destination);
if ( v7 < 100000 )
ExitProcess(0);
strcat(Destination, "@DBApp");
length = strlen(Destination);
sub_40100A((BYTE *)Destination, length, String1);
if ( !_strcmpi(String1, "6E32D0943418C2C33385BC35A1470250DD8923A9") )
{
printf("continue...\n\n");
printf("pls input the first passwd(2): ");
memset(Str, 0, sizeof(Str));
scanf("%s", Str);
if ( strlen(Str) != 6 )
{
printf("Must be 6 characters!\n");
ExitProcess(0);
}
strcat(Str, Destination);
memset(String1, 0, sizeof(String1));
v4 = strlen(Str);
sub_401019((BYTE *)Str, v4, String1);
if ( !_strcmpi("27019e688a4e62a649fd99cadaafdb4e", String1) )
{
if ( !(unsigned __int8)sub_40100F(Str) )
{
printf("Error!!\n");
ExitProcess(0);
}
printf("bye ~~\n");
}
}
return 0;
}大致逻辑如下
先输入六个字符
之后进行拼接
sub_40100A做操作进行校验通过后再次要求输入六个字符
进行拼接
sub_401019做操作后进行校验最后通过
sub_40100F校验一下
第一段验证
v7 = atoi(Destination);
if ( v7 < 100000 )
ExitProcess(0);
strcat(Destination, "@DBApp");
length = strlen(Destination);
sub_40100A((BYTE *)Destination, length, String1);推断第一次输入为6个数字且 100000 <= v7 <= 999999
数字和”@DBApp”拼接后
进入sub_40100A查看
int __cdecl sub_40100A(BYTE *pbData, DWORD dwDataLen, LPSTR lpString1)
{
return sub_401230(pbData, dwDataLen, lpString1);
}进入sub_401230查看
int __cdecl sub_401230(BYTE *pbData, DWORD dwDataLen, LPSTR lpString1)
{
int result; // eax
DWORD i; // [esp+4Ch] [ebp-28h]
CHAR String2[4]; // [esp+50h] [ebp-24h] BYREF
BYTE v6[20]; // [esp+54h] [ebp-20h] BYREF
DWORD pdwDataLen; // [esp+68h] [ebp-Ch] BYREF
HCRYPTHASH phHash; // [esp+6Ch] [ebp-8h] BYREF
HCRYPTPROV phProv; // [esp+70h] [ebp-4h] BYREF
if ( !CryptAcquireContextA(&phProv, 0, 0, 1u, 0xF0000000) )
return 0;
if ( CryptCreateHash(phProv, 0x8004u, 0, 0, &phHash) )
{
if ( CryptHashData(phHash, pbData, dwDataLen, 0) )
{
CryptGetHashParam(phHash, 2u, v6, &pdwDataLen, 0);
*lpString1 = 0;
for ( i = 0; i < pdwDataLen; ++i )
{
wsprintfA(String2, "%02X", v6[i]);
lstrcatA(lpString1, String2);
}
CryptDestroyHash(phHash);
CryptReleaseContext(phProv, 0);
result = 1;
}
else
{
CryptDestroyHash(phHash);
CryptReleaseContext(phProv, 0);
result = 0;
}
}
else
{
CryptReleaseContext(phProv, 0);
result = 0;
}
return result;
}发现是哈希算法

通过CreateHash去查询使用了什么哈希算法
ALG_ID (Wincrypt.h) - Win32 应用|微软文档 (microsoft.com)

发现是SHA1
也就是将xxxxxx@DBApp生成SHA1等于6E32D0943418C2C33385BC35A1470250DD8923A9
需要进行碰撞攻击
第二段验证
同样是输入6个字符但这次并没有限制数字了,将之前的输入拼接到这次输入的后面,带入sub_401019。
这次也是哈希算法,ALG_ID为0x8003

这次使用的是MD5
也就是加入18的位字符串
要求生成的MD5值为27019e688a4e62a649fd99cadaafdb4e。
这种不太好攻击,再看最后的验证
最后验证
验证拼接的18位字符
xxxxxxxxxxxx@DBApp
算法如下,返回1代表通过验证:
char __cdecl sub_4014D0(LPCSTR lpString)
{
LPCVOID lpBuffer; // [esp+50h] [ebp-1Ch]
DWORD NumberOfBytesWritten; // [esp+58h] [ebp-14h] BYREF
DWORD nNumberOfBytesToWrite; // [esp+5Ch] [ebp-10h]
HGLOBAL hResData; // [esp+60h] [ebp-Ch]
HRSRC hResInfo; // [esp+64h] [ebp-8h]
HANDLE hFile; // [esp+68h] [ebp-4h]
hFile = 0;
hResData = 0;
nNumberOfBytesToWrite = 0;
NumberOfBytesWritten = 0;
hResInfo = FindResourceA(0, (LPCSTR)0x65, "AAA");
if ( !hResInfo )
return 0;
nNumberOfBytesToWrite = SizeofResource(0, hResInfo);
hResData = LoadResource(0, hResInfo);
if ( !hResData )
return 0;
lpBuffer = LockResource(hResData);
sub_401005(lpString, (int)lpBuffer, nNumberOfBytesToWrite);
hFile = CreateFileA("dbapp.rtf", 0x10000000u, 0, 0, 2u, 0x80u, 0);
if ( hFile == (HANDLE)-1 )
return 0;
if ( !WriteFile(hFile, lpBuffer, nNumberOfBytesToWrite, &NumberOfBytesWritten, 0) )
return 0;
CloseHandle(hFile);
return 1;
}发现这是一个生成Flag文件的函数
要求就是用户之前的输入正确,再提取程序中的AAA资源文件。
将两者再通过算法搅在一起,最后生成正确的Flag文件。
看看处理函数sub_401005,指向sub_401420
unsigned int __cdecl sub_401420(LPCSTR input, int resfile, int length_res)
{
unsigned int result; // eax
unsigned int i; // [esp+4Ch] [ebp-Ch]
unsigned int length_input; // [esp+54h] [ebp-4h]
length_input = lstrlenA(input);
for ( i = 0; ; ++i )
{
result = i;
if ( i >= length_res )
break;
*(_BYTE *)(i + resfile) ^= input[i % length_input];
}
return result;
}简单的用输入的18位 对 文件内容 按位异或
要解密文件,那我们必须要前六位的内容
于是可以猜测文件遵循RTF格式的文件头,那么前六位应当是固定的。
再利用资源文件可以逆向计算出前六位的输入
而RTF标准的前六位格式如图
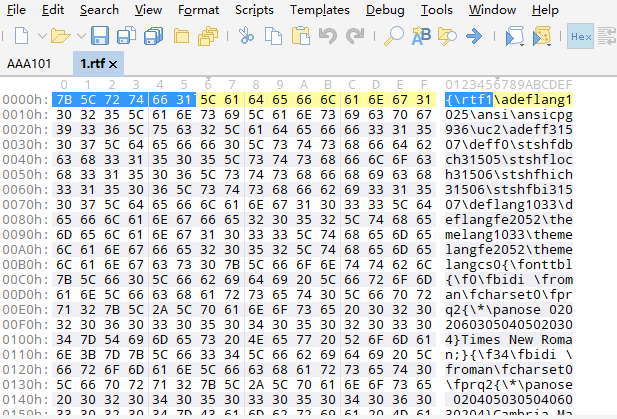
由字符串``{\rtf1`构成
于是通过python脚本计算一下
str1 = r"{\rtf1"
flag1 = ''
with open('AAA101','rb+') as f:
f = f.read()
for i in range(len(str1)):
flag1 += chr(ord(str1[i]) ^ f[i])
print(flag1)得到该6位为~!3a@0
解密脚本
分为两段
前6位通过文件头解密
str1 = r"{\rtf1"
flag1 = ''
with open('AAA101','rb+') as f:
f = f.read()
for i in range(len(str1)):
flag1 += chr(ord(str1[i]) ^ f[i])
print(flag1)后6位通过sha1爆破解密
得结果为~!3a@0123321@DBApp
import hashlib
#6E32D0943418C2C33385BC35A1470250DD8923A9
dest = '6E32D0943418C2C33385BC35A1470250DD8923A9'.lower()
for i in range(100000, 999999):
str1 = b'@DBApp'
temp = hashlib.sha1(bytes(i) + str1)
temp = temp.hexdigest()
print(temp)
if temp == dest:
print(str(i) + str1.decode())
break;最后加上6位固定字符串@DBApp
即可得到18位的flag
拼凑后为~!3a@0123321@DBApp
测试结果
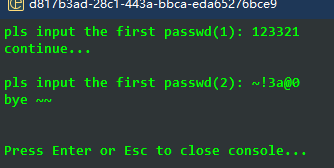
可以看到已经触发了生成Flag文件的逻辑,猜想正确。
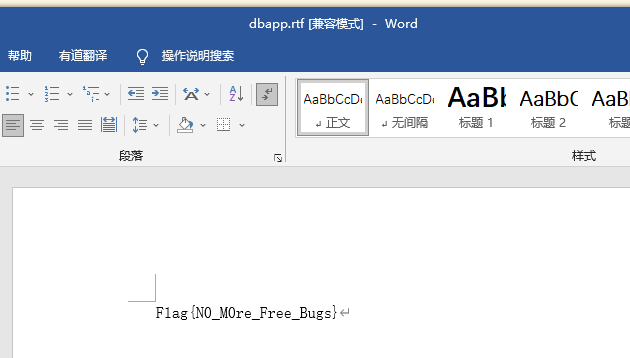
也成功拿到Flag
[2019红帽杯]easyRE(好评)
第一次上当
主要逻辑
这题没符号,不知道能不能恢复,下来查一波。
带着耐心猜测辨认一下哪些是系统函数。
通过找字符串定位sub_4009C6
随便命名了一波 大致如下
__int64 sub_4009C6()
{
__int64 result; // rax
int i; // [rsp+Ch] [rbp-114h]
__int64 v2; // [rsp+10h] [rbp-110h]
__int64 v3; // [rsp+18h] [rbp-108h]
__int64 v4; // [rsp+20h] [rbp-100h]
__int64 v5; // [rsp+28h] [rbp-F8h]
__int64 v6; // [rsp+30h] [rbp-F0h]
__int64 v7; // [rsp+38h] [rbp-E8h]
__int64 v8; // [rsp+40h] [rbp-E0h]
__int64 v9; // [rsp+48h] [rbp-D8h]
__int64 v10; // [rsp+50h] [rbp-D0h]
__int64 v11; // [rsp+58h] [rbp-C8h]
char v12[48]; // [rsp+60h] [rbp-C0h] BYREF
char input[32]; // [rsp+90h] [rbp-90h] BYREF
int v14; // [rsp+B0h] [rbp-70h]
char v15; // [rsp+B4h] [rbp-6Ch]
char v16[72]; // [rsp+C0h] [rbp-60h] BYREF
unsigned __int64 v17; // [rsp+108h] [rbp-18h]
v17 = __readfsqword(0x28u);
qmemcpy(v12, "Iodl>Qnb(ocy\x7Fy.i\x7Fd`3w}wek9{iy=~yL@EC", 36);
memset(input, 0, sizeof(input));
v14 = 0;
v15 = 0;
Sysread(0, input, 37uLL);
v15 = 0;
if ( length(input) == 36 )
{
for ( i = 0; i < (unsigned __int64)length(input); ++i )
{
if ( (unsigned __int8)(input[i] ^ i) != v12[i] )
{
result = 4294967294LL;
goto LABEL_13;
}
}
print((__int64)"continue!");
memset(v16, 0, 64uLL);
v16[64] = 0;
Sysread(0, v16, 64uLL);
v16[39] = 0;
if ( length(v16) == 39 )
{
v2 = base64(v16);
v3 = base64(v2);
v4 = base64(v3);
v5 = base64(v4);
v6 = base64(v5);
v7 = base64(v6);
v8 = base64(v7);
v9 = base64(v8);
v10 = base64(v9);
v11 = base64(v10);
if ( !(unsigned int)sub_400360(v11, off_6CC090) )
{
print((__int64)"You found me!!!");
print((__int64)"bye bye~");
}
result = 0LL;
}
else
{
result = 4294967293LL;
}
}
else
{
result = 0xFFFFFFFFLL;
}
LABEL_13:
if ( __readfsqword(0x28u) != v17 )
sub_444020();
return result;
}一阶段输入长度36的字符串
通过异或计算和v12数组比较
比对成功后进入二阶段
二阶段输入长度为39
猜测进行了疯狂的base64操作
最后进行比对
一阶段
通过脚本
p1 = 'Iodl>Qnb(ocy\x7Fy.i\x7Fd`3w}wek9{iy=~yL@EC'
flag1 = ''
for i in range(36):
flag1 += chr(ord(p1[i]) ^ i)
print(flag1)获得一阶段输入为
Info:The first four chars are `flag`这既是输入也是对我们的提示,有点小巧妙。
二阶段
最开始还没看明白为啥这么多base64
后面看到的超长字符串 才意识到可能是进行了多次base64编码
将最后比对的字符串导出
进行解密
p2 = b'Vm0wd2VHUXhTWGhpUm1SWVYwZDRWVll3Wkc5WFJsbDNXa1pPVlUxV2NIcFhhMk0xVmpKS1NHVkdXbFpOYmtKVVZtcEtTMUl5VGtsaVJtUk9ZV3hhZVZadGVHdFRNVTVYVW01T2FGSnRVbGhhVjNoaFZWWmtWMXBFVWxSTmJFcElWbTAxVDJGV1NuTlhia0pXWWxob1dGUnJXbXRXTVZaeVdrWm9hVlpyV1hwV1IzaGhXVmRHVjFOdVVsWmlhMHBZV1ZSR1lWZEdVbFZTYlhSWFRWWndNRlZ0TVc5VWJGcFZWbXR3VjJKSFVYZFdha1pXWlZaT2NtRkhhRk5pVjJoWVYxZDBhMVV3TlhOalJscFlZbGhTY1ZsclduZGxiR1J5VmxSR1ZXSlZjRWhaTUZKaFZqSktWVkZZYUZkV1JWcFlWV3BHYTFkWFRrZFRiV3hvVFVoQ1dsWXhaRFJpTWtsM1RVaG9hbEpYYUhOVmJUVkRZekZhY1ZKcmRGTk5Wa3A2VjJ0U1ExWlhTbFpqUldoYVRVWndkbFpxUmtwbGJVWklZVVprYUdFeGNHOVhXSEJIWkRGS2RGSnJhR2hTYXpWdlZGVm9RMlJzV25STldHUlZUVlpXTlZadE5VOVdiVXBJVld4c1dtSllUWGhXTUZwell6RmFkRkpzVWxOaVNFSktWa1phVTFFeFduUlRhMlJxVWxad1YxWnRlRXRXTVZaSFVsUnNVVlZVTURrPQ=='
for i in range(10):
p2 = base64.b64decode(p2)
print(p2)得到字符串
https://bbs.pediy.com/thread-254172.htm解密脚本
import base64
p1 = 'Iodl>Qnb(ocy\x7Fy.i\x7Fd`3w}wek9{iy=~yL@EC'
flag1 = ''
for i in range(36):
flag1 += chr(ord(p1[i]) ^ i)
print(flag1)
p2 = b'Vm0wd2VHUXhTWGhpUm1SWVYwZDRWVll3Wkc5WFJsbDNXa1pPVlUxV2NIcFhhMk0xVmpKS1NHVkdXbFpOYmtKVVZtcEtTMUl5VGtsaVJtUk9ZV3hhZVZadGVHdFRNVTVYVW01T2FGSnRVbGhhVjNoaFZWWmtWMXBFVWxSTmJFcElWbTAxVDJGV1NuTlhia0pXWWxob1dGUnJXbXRXTVZaeVdrWm9hVlpyV1hwV1IzaGhXVmRHVjFOdVVsWmlhMHBZV1ZSR1lWZEdVbFZTYlhSWFRWWndNRlZ0TVc5VWJGcFZWbXR3VjJKSFVYZFdha1pXWlZaT2NtRkhhRk5pVjJoWVYxZDBhMVV3TlhOalJscFlZbGhTY1ZsclduZGxiR1J5VmxSR1ZXSlZjRWhaTUZKaFZqSktWVkZZYUZkV1JWcFlWV3BHYTFkWFRrZFRiV3hvVFVoQ1dsWXhaRFJpTWtsM1RVaG9hbEpYYUhOVmJUVkRZekZhY1ZKcmRGTk5Wa3A2VjJ0U1ExWlhTbFpqUldoYVRVWndkbFpxUmtwbGJVWklZVVprYUdFeGNHOVhXSEJIWkRGS2RGSnJhR2hTYXpWdlZGVm9RMlJzV25STldHUlZUVlpXTlZadE5VOVdiVXBJVld4c1dtSllUWGhXTUZwell6RmFkRkpzVWxOaVNFSktWa1phVTFFeFduUlRhMlJxVWxad1YxWnRlRXRXTVZaSFVsUnNVVlZVTURrPQ=='
for i in range(10):
p2 = base64.b64decode(p2)
print(p2)运行
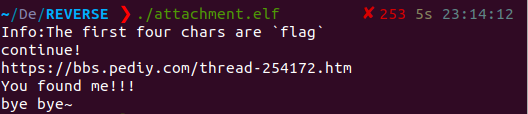
那么现在我想问
flag是啥呢?
去细读了一下文章

玩几把蛋,看来走错路了。
研究恢复符号
利用FLIRT恢复静态编译程序的符号 - 先知社区 (aliyun.com)
[转帖]分析静态编译加剥离的ELF文件的一些方法-软件逆向-看雪论坛-安全社区|安全招聘|bbs.pediy.com
IDA中提供了一个东西做FLIRT:库文件快速识别与鉴定技术(Fast Library Identification and Recognition Technology)
简单的说,这玩意,能通过一个静态链接库的签名文件,来快速识别被去符号的程序中的函数,从而为函数找到符号
lscan走起 看看把哪些库导入一波
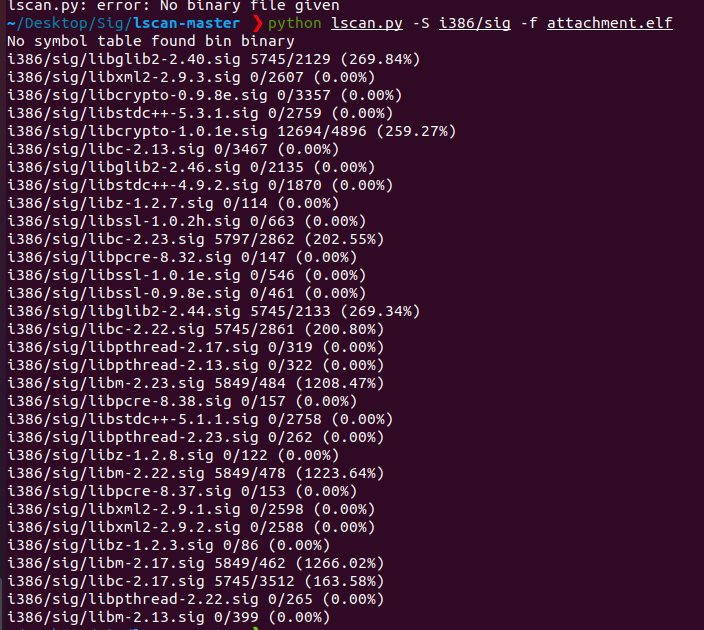
No symbol table found bin binary
i386/sig/libcrypto-1.0.1e.sig 12694/4896 (259.27%)
i386/sig/libc-2.23.sig 5797/2862 (202.55%)
i386/sig/libglib2-2.44.sig 5745/2133 (269.34%)
i386/sig/libm-2.23.sig 5849/484 (1208.47%)在IDA应用了没卵子用啊
下次遇到再试试 还得省点时间看论文呢
这波直接查了一波攻略
再接再厉
探索思路
直接查了一波攻略
发现是在数据段下面还有一些数据
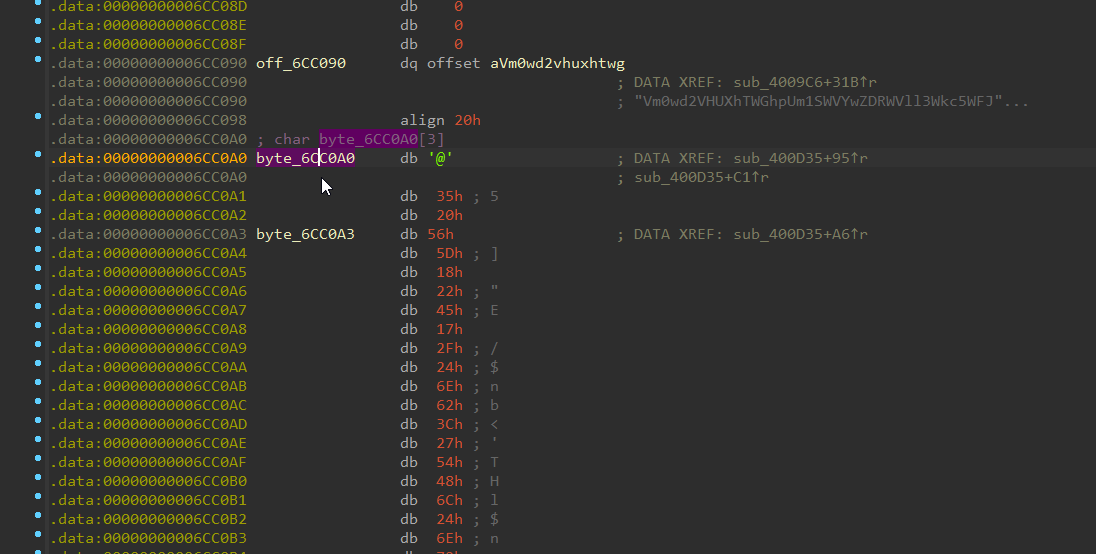
发现被函数sub_400D35引用
这个函数其实也是题目Flag真正的出处(真得脑洞大开)
看来以后还是得多注意数据段的东西,关键突破口!
进入该函数分析
unsigned __int64 sub_400D35()
{
unsigned __int64 result; // rax
unsigned int v1; // [rsp+Ch] [rbp-24h]
int i; // [rsp+10h] [rbp-20h]
int j; // [rsp+14h] [rbp-1Ch]
unsigned int v4; // [rsp+24h] [rbp-Ch]
unsigned __int64 v5; // [rsp+28h] [rbp-8h]
v5 = __readfsqword(0x28u);
v1 = sub_43FD20(0LL) - qword_6CEE38;
for ( i = 0; i <= 1233; ++i )
{
sub_40F790(v1);
sub_40FE60();
sub_40FE60();
v1 = sub_40FE60() ^ 0x98765432;
}
v4 = v1;
if ( ((unsigned __int8)v1 ^ byte_6CC0A0[0]) == 'f' && (HIBYTE(v4) ^ (unsigned __int8)byte_6CC0A3) == 'g' )
{
for ( j = 0; j <= 24; ++j )
sub_410E90((unsigned __int8)(byte_6CC0A0[j] ^ *((_BYTE *)&v4 + j % 4)));
}
result = __readfsqword(0x28u) ^ v5;
if ( result )
sub_444020();
return result;
}v1和v4大概是产生随机数,别管
直接看20行的异或判断,我们可以逆推出v1的低8位和v4的高8位的值
但这还不够,结合前面的INFO告诉我们前四位为flag
那刚好是四个四节,所以我们先通过byte_6CC0A0的前面4个字节得到v4,再用v4开始解密byte_6CC0A0
解密脚本
array = '@5 V]\x18"E\x17/$nb<\'THl$nr<2E['
key = ''
info = 'flag'
flag = ''
for i in range(0,4):
key += chr(ord(info[i]) ^ ord(array[i]))
print("key:" + key)
for i in range(len(array)):
flag += chr(ord(array[i]) ^ ord(key[i % 4]))
print(flag)最后终于拿到Flag
非常感动 真的是很有意思的一道题
[GUET-CTF2019]re
脱壳
发现是UPX壳,脱一下进IDA分析。

分析过程
再次尝试恢复符号失败
玛德还是直接硬上吧
主要逻辑
printXB((unsigned int)"input your flag:", a2, a3, a4, a5, a6, 0LL, 0LL, 0LL, 0LL);
scanfXB((unsigned int)"%s", (unsigned int)&input, v6, v7, v8, v9, input);
if ( (unsigned int)sub_4009AE(&input) )
sub_410350("Correct!");
else
sub_410350("Wrong!");
result = 0LL;接下来看看sub_4009AE
_BOOL8 __fastcall sub_4009AE(char *a1)
{
if ( 1629056 * *a1 != 166163712 )
return 0LL;
if ( 6771600 * a1[1] != 731332800 )
return 0LL;
if ( 3682944 * a1[2] != 357245568 )
return 0LL;
if ( 10431000 * a1[3] != 1074393000 )
return 0LL;
if ( 3977328 * a1[4] != 489211344 )
return 0LL;
if ( 5138336 * a1[5] != 518971936 )
return 0LL;
if ( 7532250 * a1[7] != 406741500 )
return 0LL;
if ( 5551632 * a1[8] != 294236496 )
return 0LL;
if ( 3409728 * a1[9] != 177305856 )
return 0LL;
if ( 13013670 * a1[10] != 650683500 )
return 0LL;
if ( 6088797 * a1[11] != 298351053 )
return 0LL;
if ( 7884663 * a1[12] != 386348487 )
return 0LL;
if ( 8944053 * a1[13] != 438258597 )
return 0LL;
if ( 5198490 * a1[14] != 249527520 )
return 0LL;
if ( 4544518 * a1[15] != 445362764 )
return 0LL;
if ( 3645600 * a1[17] != 174988800 )
return 0LL;
if ( 10115280 * a1[16] != 981182160 )
return 0LL;
if ( 9667504 * a1[18] != 493042704 )
return 0LL;
if ( 5364450 * a1[19] != 257493600 )
return 0LL;
if ( 13464540 * a1[20] != 767478780 )
return 0LL;
if ( 5488432 * a1[21] != 312840624 )
return 0LL;
if ( 14479500 * a1[22] != 1404511500 )
return 0LL;
if ( 6451830 * a1[23] != 316139670 )
return 0LL;
if ( 6252576 * a1[24] != 619005024 )
return 0LL;
if ( 7763364 * a1[25] != 372641472 )
return 0LL;
if ( 7327320 * a1[26] != 373693320 )
return 0LL;
if ( 8741520 * a1[27] != 498266640 )
return 0LL;
if ( 8871876 * a1[28] != 452465676 )
return 0LL;
if ( 4086720 * a1[29] != 208422720 )
return 0LL;
if ( 9374400 * a1[30] == 515592000 )
return 5759124 * a1[31] == 719890500;
return 0LL;
}好家伙
真就一个一个比对
那就搞
注意中间换了一次顺序
还有第6位没给 需要爆破
傻逼题 就很没有营养 浪费时间
[WUSTCTF2020]level1
很简单的逻辑 简单记录
主逻辑
int __cdecl main(int argc, const char **argv, const char **envp)
{
int i; // [rsp+4h] [rbp-2Ch]
FILE *stream; // [rsp+8h] [rbp-28h]
char ptr[24]; // [rsp+10h] [rbp-20h] BYREF
unsigned __int64 v7; // [rsp+28h] [rbp-8h]
v7 = __readfsqword(0x28u);
stream = fopen("flag", "r");
fread(ptr, 1uLL, 20uLL, stream);
fclose(stream);
for ( i = 1; i <= 19; ++i )
{
if ( (i & 1) != 0 )
printf("%ld\n", (unsigned int)(ptr[i] << i));
else
printf("%ld\n", (unsigned int)(i * ptr[i]));
}
return 0;
}解密脚本
with open('[WUSTCTF2020]level1\output.txt','r') as f:
flag = ''
for i in range(1, 20):
temp = f.readline()
print(type(temp))
if i & 1 != 0:
tem = chr(int(temp) >> i)
flag += tem
else:
tem = chr(int(temp) // i)
flag += tem
print(flag)[MRCTF2020]Transform
关键逻辑
int __cdecl main(int argc, const char **argv, const char **envp)
{
char Str[104]; // [rsp+20h] [rbp-70h] BYREF
int j; // [rsp+88h] [rbp-8h]
int i; // [rsp+8Ch] [rbp-4h]
sub_402230(argc, argv, envp);
printf("Give me your code:\n");
scanf("%s", Str);
if ( strlen(Str) != 33 ) // 长度33
{
printf("Wrong!\n");
system("pause");
exit(0);
}
for ( i = 0; i <= 32; ++i ) // 按位处理
{
byte_414040[i] = Str[dword_40F040[i]];
byte_414040[i] ^= LOBYTE(dword_40F040[i]);
}
for ( j = 0; j <= 32; ++j ) // 按位比较
{
if ( byte_40F0E0[j] != byte_414040[j] )
{
printf("Wrong!\n");
system("pause");
exit(0);
}
}
printf("Right!Good Job!\n");
printf("Here is your flag: %s\n", Str);
system("pause");
return 0;
}长度为33
解密脚本
每四个字节取单字节整数 有练习到切片
dword_40F040 = b'\t\x00\x00\x00\n\x00\x00\x00\x0f\x00\x00\x00\x17\x00\x00\x00\x07\x00\x00\x00\x18\x00\x00\x00\x0c\x00\x00\x00\x06\x00\x00\x00\x01\x00\x00\x00\x10\x00\x00\x00\x03\x00\x00\x00\x11\x00\x00\x00 \x00\x00\x00\x1d\x00\x00\x00\x0b\x00\x00\x00\x1e\x00\x00\x00\x1b\x00\x00\x00\x16\x00\x00\x00\x04\x00\x00\x00\r\x00\x00\x00\x13\x00\x00\x00\x14\x00\x00\x00\x15\x00\x00\x00\x02\x00\x00\x00\x19\x00\x00\x00\x05\x00\x00\x00\x1f\x00\x00\x00\x08\x00\x00\x00\x12\x00\x00\x00\x1a\x00\x00\x00\x1c\x00\x00\x00\x0e\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00'
byte_40F0E0 = b'gy{\x7fu+<RSyW^]B{-*fB~LWyAk~e<\\EobM'
byte_414040 = ''
index = dword_40F040[::4]
print(index)
for i in range(33):
byte_414040 += chr(index[i] ^ byte_40F0E0[i])
print(byte_414040)
a = [''] * 33
for i in range(33):
a[index[i]] += byte_414040[i]
for i in range(len(a)):
print(a[i],end='')Youngter-drive(好评)
关键函数
int __cdecl main_0(int argc, const char **argv, const char **envp)
{
HANDLE v4; // [esp+D0h] [ebp-14h]
HANDLE hObject; // [esp+DCh] [ebp-8h]
((void (*)(void))sub_4110FF)(); // 录入%36s的字符
::hObject = CreateMutexW(0, 0, 0);
j_strcpy(Destination, &Source);
hObject = CreateThread(0, 0, StartAddress, 0, 0, 0);// 线程1
v4 = CreateThread(0, 0, sub_41119F, 0, 0, 0); // 线程2
CloseHandle(hObject);
CloseHandle(v4);
while ( dword_418008 != -1 ) // 执行完毕
;
sub_411190(); // 比对结果
CloseHandle(::hObject);
return 0;
}sub_4110FF录入输入// attributes: thunk int sub_4110FF(void) { return sub_411BD0(); } int sub_411BD0() { printf( "1111111111111111111111111111111111111111111111111111111111111111111111111111111\n" "*******************************************************************************\n" "************** ****************************************************\n" "************** ******** ********************* *************\n" "************** ********* ********************* ***************************\n" "************** ********* ********************* ***************************\n" "************** ********* ********************* ***************************\n" "************** ******* ********************** ***************************\n" "************** **** ************************* ***************************\n" "************** * *************************** **************\n" "************** *** ************************* ***************************\n" "************** ****** *********************** ***************************\n" "************** ******** ********************* ***************************\n" "************** ********** ******************* ***************************\n" "************** *********** ***************** *************\n" "*******************************************************************************\n" "1111111111111111111111111111111111111111111111111111111111111111111111111111111\n"); printf("input flag:\n"); return scanf("%36s", Source);StartAddressvoid __stdcall StartAddress_0(int a1) { while ( 1 ) { WaitForSingleObject(hObject, 0xFFFFFFFF); if ( dword_418008 > -1 ) { sub_41112C(&Source, dword_418008); // 处理对应字符 --dword_418008; Sleep(0x64u); } ReleaseMutex(hObject); } } // attributes: thunk char *__cdecl sub_41112C(int a1, int a2) { return sub_411940(a1, a2); } // positive sp value has been detected, the output may be wrong! char *__cdecl sub_411940(int a1, int a2) { char *result; // eax char v3; // [esp+D3h] [ebp-5h] v3 = *(_BYTE *)(a2 + a1); if ( (v3 < 97 || v3 > 122) && (v3 < 65 || v3 > 90) )// 要求为字母 exit(0); if ( v3 < 97 || v3 > 122 ) // 大写字母对应表后26位 { result = off_418000[0]; *(_BYTE *)(a2 + a1) = off_418000[0][*(char *)(a2 + a1) - 38]; } else // 小写字母对应表前26位 { result = off_418000[0]; *(_BYTE *)(a2 + a1) = off_418000[0][*(char *)(a2 + a1) - 96]; } return result; }sub_41119F// attributes: thunk DWORD __stdcall sub_41119F(LPVOID lpThreadParameter) { return sub_411B10(lpThreadParameter); } void __stdcall sub_411B10(int a1) { while ( 1 ) { WaitForSingleObject(hObject, 0xFFFFFFFF); if ( dword_418008 > -1 ) { Sleep(0x64u); --dword_418008; } ReleaseMutex(hObject); } }sub_411190// attributes: thunk int sub_411190(void) { return sub_411880(); } int sub_411880() { int i; // [esp+D0h] [ebp-8h] for ( i = 0; i < 29; ++i ) { if ( Source[i] != off_418004[i] ) exit(0); } return printf("\nflag{%s}\n\n", Destination); }
流程分析
主函数通过打开了两个线程来处理输入
线程1和线程2通过Sleep交替执行
每执行一次将dword_418008减一 其初始值为29
- 线程1处理
input[dword_418008]的输入
input长度为29 所以第一次不会处理
- 线程2不处理输入 单纯将
dword_418008减1
也就是隔一位处理一位 处理的起始点为字符串倒数第二个字符 方向向前
解密脚本
#最终比对
off_418004 = 'TOiZiZtOrYaToUwPnToBsOaOapsyS\x00'
#线程处理表
off_418000 = 'QWERTYUIOPASDFGHJKLZXCVBNMqwertyuiopasdfghjklzxcvbnm'
def look_v(a1):
index = 0
for i in range(len(off_418000)):
if a1 == off_418000[i]:
index = i
break;
if 0 <= index <= 25:
res = chr(index + 96)
else:
res = chr(index + 38)
return res
flag = list(str(off_418004))
for i in range(len(off_418004)):
if i % 2 == 0:
flag[29-i] = look_v(off_418004[29-i])
print(''.join([c for c in flag]))
PS: 为了正常执行程序 在输入最后要随便加一位 按理说是 buuoj上只能提交E
[FlareOn6]Overlong
对数据段进行解码
题目信息
int __stdcall start(int a1, int a2, int a3, int a4)
{
CHAR Text[128]; // [esp+0h] [ebp-84h] BYREF
unsigned int v6; // [esp+80h] [ebp-4h]
v6 = sub_401160(Text, (int)&unk_402008, 0x1Cu); //长度28
Text[v6] = 0;
MessageBoxA(0, Text, Caption, 0);
return 0;
}sub_401160对unk_402008进行解密,赋值到text中。
最后直接弹出消息,直接打开程序效果如下
发现没给出关键信息,而去看数据段其实长度有175,而函数中只用到了28的长度
所以这里可以猜到如果将完整的数据段解密即可拿到flag
静态方法
思路就是通过模仿正向算法将完整的数据段进行解码
具体函数
unsigned int __cdecl sub_401160(char *a1, int rdata, unsigned int a3)
{
unsigned int i; // [esp+4h] [ebp-4h]
for ( i = 0; i < a3; ++i ) // 长度28
{
rdata += sub_401000(a1, (char *)rdata);
if ( !*a1++ )
break;
}
return i;
}这里每产生一个字符后就将rdata向前推进
生成字符的函数sub_401000如下
int __cdecl sub_401000(_BYTE *flag, char *rdata)
{
int v3; // [esp+0h] [ebp-8h]
char v4; // [esp+4h] [ebp-4h]
if ( (int)(unsigned __int8)*rdata >> 3 == 30 )
{
v4 = rdata[3] & 0x3F | ((rdata[2] & 0x3F) << 6);
v3 = 4;
}
else if ( (int)(unsigned __int8)*rdata >> 4 == 14 )
{
v4 = rdata[2] & 0x3F | ((rdata[1] & 0x3F) << 6);
v3 = 3;
}
else if ( (int)(unsigned __int8)*rdata >> 5 == 6 )
{
v4 = rdata[1] & 0x3F | ((*rdata & 0x1F) << 6);
v3 = 2;
}
else
{
v4 = *rdata;
v3 = 1;
}
*flag = v4;
return v3;
}这里是根据rdata当前位的值来决定 每1/2/3/4位生成一个字符
我们要将完整的数据段解码就一直循环这个函数到数据段数据结束为止
解密脚本如下
rdata = '\xe0\x81\x89\xc0\xa0\xc1\xae\xe0\x81\xa5\xc1\xb6\xf0\x80\x81\xa5\xe0\x81\xb2\xf0\x80\x80\xa0\xe0\x81\xa2ro\xc1\xabe\xe0\x80\xa0\xe0\x81\xb4\xe0\x81\xa8\xc1\xa5 \xc1\xa5\xe0\x81\xaec\xc1\xaf\xe0\x81\xa4\xf0\x80\x81\xa9n\xc1\xa7\xc0\xba I\xf0\x80\x81\x9f\xc1\xa1\xc1\x9f\xc1\x8d\xe0\x81\x9f\xc1\xb4\xf0\x80\x81\x9f\xf0\x80\x81\xa8\xc1\x9f\xf0\x80\x81\xa5\xe0\x81\x9f\xc1\xa5\xe0\x81\x9f\xf0\x80\x81\xae\xc1\x9f\xf0\x80\x81\x83\xc1\x9f\xe0\x81\xaf\xe0\x81\x9f\xc1\x84_\xe0\x81\xa9\xf0\x80\x81\x9fn\xe0\x81\x9f\xe0\x81\xa7\xe0\x81\x80\xf0\x80\x81\xa6\xf0\x80\x81\xac\xe0\x81\xa1\xc1\xb2\xc1\xa5\xf0\x80\x80\xad\xf0\x80\x81\xafn\xc0\xae\xf0\x80\x81\xa3o\xf0\x80\x81\xad'
data = list(rdata)
flag = ''
j = 0
while(j < len(rdata)):
if ord(rdata[j]) >> 3 == 30:
flag += chr(ord(rdata[3 + j]) & 0x3f | ((ord(rdata[2 + j]) & 0x3f) << 6))
j += 4
elif ord(rdata[j]) >> 4 == 14:
flag += chr(ord(rdata[2 + j]) & 0x3f | ((ord(rdata[1 + j]) & 0x3f) << 6))
j += 3
elif ord(rdata[j]) >> 5 == 6:
flag += chr(ord(rdata[1 + j]) & 0x3f | ((ord(rdata[0 + j]) & 0x1f) << 6))
j += 2
else:
flag += rdata[j]
j += 1
print(flag)动态方法
这道题前面没动脑子 静态做完了之后才发现动态其实最快
因为题目自己会运行解密函数,只是因为长度没给够所以不会打印出flag。
那么我们只需要把sub_401160函数的长度参数给扩大到175(完整数据段的长度)就能看到flag了
那么就开始调试程序
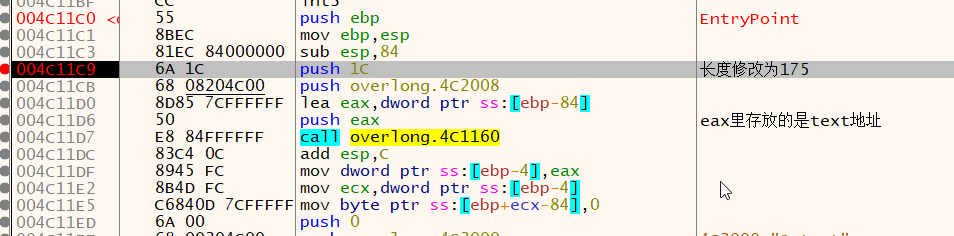
在push 1C执行之后将栈顶从0x1C修改为0XAF
接着关注text地址空间,在执行完4c1160函数后查看text地址空间。

直接能看到flag内容
顺便练习下导出的脚本
import binascii
flag = '49 20 6E 65 76 65 72 20 62 72 6F 6B 65 20 74 68 65 20 65 6E 63 6F 64 69 6E 67 3A 20 49 5F 61 5F 4D 5F 74 5F 68 5F 65 5F 65 5F 6E 5F 43 5F 6F 5F 44 5F 69 5F 6E 5F 67 40 66 6C 61 72 65 2D 6F 6E 2E 63 6F 6D'
new = ''
for i in range(len(flag)):
if flag[i] != ' ':
new += flag[i]
print(binascii.unhexlify(new))Java/Android
Reverse
题目就是一个Reverse.class文件
将class文件拖入JD-GUI分析
看到内容如下
import java.util.ArrayList;
import java.util.Scanner;
public class Reverse {
public static void main(String[] args) {
Scanner s = new Scanner(System.in);
System.out.println("Please input the flag );
String str = s.next();
System.out.println("Your input is );
System.out.println(str);
char[] stringArr = str.toCharArray();
Encrypt(stringArr);
}
public static void Encrypt(char[] arr) {
ArrayList<Integer> Resultlist = new ArrayList<>();
for (int i = 0; i < arr.length; i++) {
int result = arr[i] + 64 ^ 0x20;
Resultlist.add(Integer.valueOf(result));
}
int[] KEY = {
180, 136, 137, 147, 191, 137, 147, 191, 148, 136,
133, 191, 134, 140, 129, 135, 191, 65 };
ArrayList<Integer> KEYList = new ArrayList<>();
for (int j = 0; j < KEY.length; j++)
KEYList.add(Integer.valueOf(KEY[j]));
System.out.println("Result:");
if (Resultlist.equals(KEYList)) {
System.out.println("Congratulations);
} else {
System.err.println("Error);
}
}
}直接逆向解密一下就可以
if __name__ == '__main__':
flag = ''
Key = [180, 136, 137, 147, 191, 137, 147, 191, 148, 136,
133, 191, 134, 140, 129, 135, 191, 65]
for i in range(len(Key)):
temp = Key[i] ^ 0x20
temp -= 64
flag += chr(temp)
print(flag[i],end='')简单注册器
使用Smali2Java将APK反编译并将smali转换成java代码
Smali2Java翻译的代码有错 shit 换成JEB之后就好了
使用JEB将APK反编译并将smali转换成java代码
找到关键逻辑如下
package com.example.flag;
import android.os.Bundle;
import android.support.v4.app.Fragment;
import android.support.v7.app.ActionBarActivity;
import android.view.LayoutInflater;
import android.view.Menu;
import android.view.MenuItem;
import android.view.View.OnClickListener;
import android.view.View;
import android.view.ViewGroup;
import android.widget.Button;
import android.widget.EditText;
import android.widget.TextView;
public class MainActivity extends ActionBarActivity {
public static class PlaceholderFragment extends Fragment {
@Override // android.support.v4.app.Fragment
public View onCreateView(LayoutInflater arg4, ViewGroup arg5, Bundle arg6) {
return arg4.inflate(0x7F030018, arg5, false); // layout:fragment_main
}
}
@Override // android.support.v7.app.ActionBarActivity
protected void onCreate(Bundle arg7) {
super.onCreate(arg7);
this.setContentView(0x7F030017); // layout:activity_main
if(arg7 == null) {
this.getSupportFragmentManager().beginTransaction().add(0x7F05003C, new PlaceholderFragment()).commit(); // id:container
}
Button button = (Button)this.findViewById(0x7F05003F); // id:button1
TextView textview = (TextView)this.findViewById(0x7F05003E); // id:textView1
button.setOnClickListener(new View.OnClickListener() {
@Override // android.view.View$OnClickListener
public void onClick(View arg13) {
int flag = 1;
String xx = ((EditText)this.findViewById(0x7F05003D)).getText().toString(); // id:editText1
if(xx.length() != 0x20 || xx.charAt(0x1F) != 97 || xx.charAt(1) != 98 || xx.charAt(0) + xx.charAt(2) - 0x30 != 56) {
flag = 0;
}
if(flag == 1) {
char[] x = "dd2940c04462b4dd7c450528835cca15".toCharArray();
x[2] = (char)(x[2] + x[3] - 50);
x[4] = (char)(x[2] + x[5] - 0x30);
x[30] = (char)(x[0x1F] + x[9] - 0x30);
x[14] = (char)(x[27] + x[28] - 97);
int i;
for(i = 0; i < 16; ++i) {
char a = x[0x1F - i];
x[0x1F - i] = x[i];
x[i] = a;
}
textview.setText("flag{" + String.valueOf(x) + "}");
return;
}
textview.setText("输入注册码错误");
}
});
}
@Override // android.app.Activity
public boolean onCreateOptionsMenu(Menu arg3) {
this.getMenuInflater().inflate(0x7F0C0000, arg3); // menu:main
return true;
}
@Override // android.app.Activity
public boolean onOptionsItemSelected(MenuItem arg3) {
return arg3.getItemId() == 0x7F050040 ? true : super.onOptionsItemSelected(arg3); // id:action_settings
}
}
直接正向输入
发现判断逻辑很短
- 长度为32
- (xx.charAt(0x1f) != 0x61) || 最后一位a
- (xx.charAt(0x1) != 0x62) || 第二位b
- (((xx.charAt(0x0) + xx.charAt(0x2)) - 0x30) != 0x38) || xx[0] + xx[3] = 0x68
直接构造满足条件的字符串
0b8xxxxxxxxxxxxxxxxxxxxxxxxxxxxa
flag{59acc538825054c7de4b26440c0999dd}

算法计算
抄一个正向的代码
if __name__ == "__main__":
flagtrue = 'dd2940c04462b4dd7c450528835cca15'
a = list(flagtrue)
a[2] = chr(ord(a[2])+ord(a[3]) - 0x32)
a[4] = chr(ord(a[2])+ord(a[5]) - 0x30)
a[0x1e] = chr(ord(a[0x1f])+ord(a[0x9]) - 0x30)
a[0xe] = chr(ord(a[0x1b])+ord(a[0x1c]) - 0x61)
for i in range(0x10):
ch = a[0x1f - i]
a[0x1f - i] = a[i]
a[i] = ch
for i in range(len(a)):
print(a[i],end='')计算得Flag = ‘59acc538825054c7de4b26440c0999dd’
相册
题目介绍:
你好,这是上次聚会相片,你看看(病毒,不建议安装到手机,提取完整邮箱即为flag) 注意:得到的 flag 请包上 flag{} 提交
APK分析
APK拖入jadx-gui
从题目描述可以搜索一下mail相关的代码
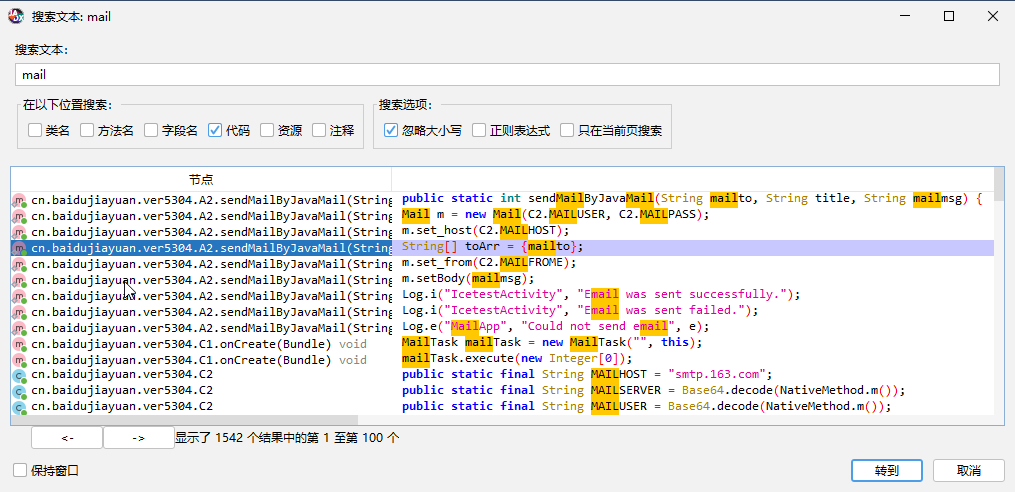
定位到sendMailByJavaMail函数
public static int sendMailByJavaMail(String mailto, String title, String mailmsg) {
if (!debug) {
Mail m = new Mail(C2.MAILUSER, C2.MAILPASS);
m.set_host(C2.MAILHOST);
m.set_port(C2.PORT);
m.set_debuggable(true);
String[] toArr = {mailto};
m.set_to(toArr);
m.set_from(C2.MAILFROME);
m.set_subject(title);
m.setBody(mailmsg);
try {
if (m.send()) {
Log.i("IcetestActivity", "Email was sent successfully.");
} else {
Log.i("IcetestActivity", "Email was sent failed.");
}
} catch (Exception e) {
Log.e("MailApp", "Could not send email", e);
}
}
return 1;
}
定位到C2类
public class C2 {
public static final String CANCELNUMBER = "%23%2321%23";
public static final String MAILHOST = "smtp.163.com";
public static final String MOVENUMBER = "**21*121%23";
public static final String PORT = "25";
public static final String date = "2115-11-1";
public static final String MAILSERVER = Base64.decode(NativeMethod.m());
public static final String MAILUSER = Base64.decode(NativeMethod.m());
public static final String MAILPASS = Base64.decode(NativeMethod.pwd());
public static final String MAILFROME = Base64.decode(NativeMethod.m());
public static final String phoneNumber = Base64.decode(NativeMethod.p());
static {
System.loadLibrary("core");
}
public static Date strToDateLong(String strDate) {
SimpleDateFormat formatter = new SimpleDateFormat("yyyy-MM-dd");
ParsePosition pos = new ParsePosition(0);
Date strtodate = formatter.parse(strDate, pos);
return strtodate;
}
public static boolean isFilter(Context context) {
Date lastN = strToDateLong(date);
Date currentTime = new Date();
return lastN.getTime() - currentTime.getTime() < 0;
}
public static boolean isServerFilter(Context context) {
SharedPreferences mSharedPreferences = context.getSharedPreferences("X", 0);
String m = mSharedPreferences.getString("m", A2.FILTERSETUPTAG);
if (m.equals(A2.FILTERSETUPTAG)) {
return true;
}
return false;
}
}发现MAILSERVER = Base64.decode(NativeMethod.m());
于是需要定位到Native代码的m方法
将其中的返回的字符串进行Base64解码即可获得邮箱地址
Native分析
定位到方法m
int __fastcall Java_com_net_cn_NativeMethod_m(int a1)
{
return (*(int (__fastcall **)(int, const char *))(*(_DWORD *)a1 + 668))(a1, "MTgyMTg0NjUxMjVAMTYzLmNvbQ==");
}看到base64编码直接给了,完成!
解密脚本
import base64
print(base64.b64decode('MTgyMTg0NjUxMjVAMTYzLmNvbQ=='))迷宫/小游戏
不一样的Flag
题目大概是一个走迷宫的小游戏
Flag就是走迷宫的顺序
主逻辑如图
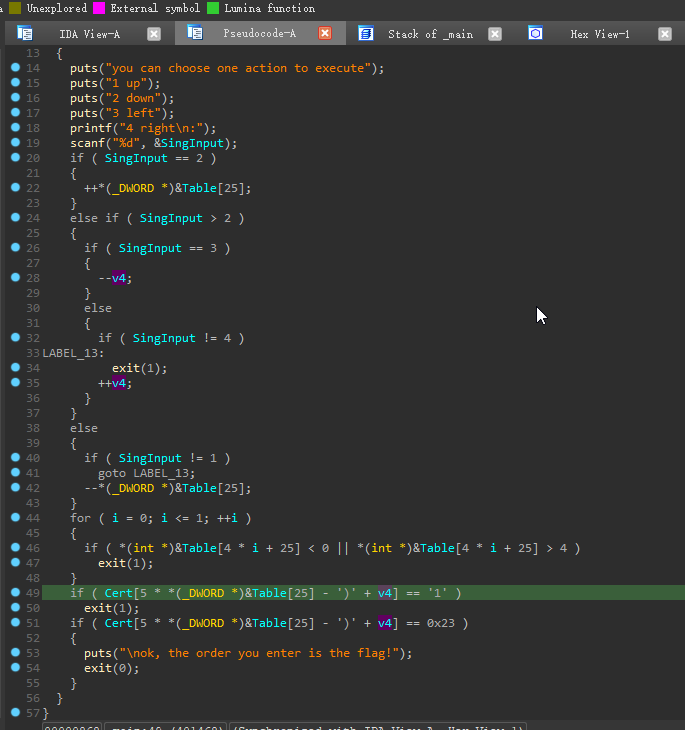
拆解一下游戏玩法
//开局信息
v4 = 0;
strcpy(Table, "*11110100001010000101111#"); //长度25的字符串
2A 31 31 31 31 30 31 30 30 30 30 31 30 31 30 30
30 30 31 30 31 31 31 31 23 00 00 00 FF FF FF FF
//用户可操作选择
if ( SingInput == 1 )
--*(_DWORD *)&Table[25]; //up
if ( SingInput == 2 )
++*(_DWORD *)&Table[25]; //down
if ( SingInput == 3 )
--v4; //left
if ( SingInput == 4 )
++v4; //right
//验证逻辑
for ( i = 0; i <= 1; ++i )
{
if ( *(int *)&Table[4 * i + 25] < 0 || *(int *)&Table[4 * i + 25] > 4 )
exit(1);
}
if ( Cert[5 * *(_DWORD *)&Table[25] - 41 + v4] == '1' )
exit(1);
if ( Cert[5 * *(_DWORD *)&Table[25] - 41 + v4] == 35 )
{
puts("\nok, the order you enter is the flag!");
exit(0);
}在这里我不知道CERT的值 所以会感觉无从下手
但看到迷宫验证的时候是5成一排
*1111
01000
01010
00010
1111#按照提示走迷宫
得到222441144222
尝试之后正确
可以得知Cert[5 * *(_DWORD *)&Table[25] - 41 + v4]就是我们迷宫当前所在的位置
Maze
分析过程
先处理一下花指令

在函数开头重新生成函数
int __cdecl main(int argc, const char **argv, const char **envp)
{
int i; // [esp+10h] [ebp-14h]
char input[16]; // [esp+14h] [ebp-10h] BYREF
printf(aGoThroughTheMa);
scanf("%14s", input);
for ( i = 0; i <= 13; ++i )
{
switch ( input[i] )
{
case 'a':
--*(_DWORD *)asc_408078; // left
break;
case 'd':
++*(_DWORD *)asc_408078; // right
break;
case 's':
--dword_40807C; // down
break;
case 'w':
++dword_40807C; // up
break;
default:
continue;
}
}
if ( *(_DWORD *)asc_408078 == 5 && dword_40807C == -4 )
{
printf(aCongratulation);
printf(aHereIsTheFlagF);
}
else
{
printf(aTryAgain);
}
return 0;
}发现关键变量
asc_408078 db 7
dword_40807C dd 0
maze = '*******+********* ****** **** ******* **F****** **************'最终需要*(_DWORD *)asc_408078 == 5 && dword_40807C == -4
画迷宫
maze = '*******+********* ****** **** ******* **F****** **************'
print(len(maze))
temp = 0
for i in range(70):
print(maze[i],end='')
temp += 1
if temp == 10:
print('')
temp = 0得到迷宫如下
*******+**
******* **
**** **
** *****
** **F****
** ****
**********于是得flag{ssaaasaassdddw}
[ACTF新生赛2020]Oruga
是个迷宫题 还是调试了一会儿才完全明白
迷宫判定逻辑
_BOOL8 __fastcall sub_55AB2F80078A(__int64 input)
{
int v2; // [rsp+Ch] [rbp-Ch]
int v3; // [rsp+10h] [rbp-8h]
int v4; // [rsp+14h] [rbp-4h]
v2 = 0;
v3 = 5;
v4 = 0;
while ( byte_55AB2FA01020[v2] != '!' )
{
v2 -= v4; // 撞墙后退一步
if ( *(_BYTE *)(v3 + input) != 'W' || v4 == -16 )
{
if ( *(_BYTE *)(v3 + input) != 'E' || v4 == 1 )
{
if ( *(_BYTE *)(v3 + input) != 'M' || v4 == 16 )
{
if ( *(_BYTE *)(v3 + input) != 'J' || v4 == -1 )
return 0LL;
v4 = -1;
}
else
{
v4 = 16;
}
}
else
{
v4 = 1;
}
}
else
{
v4 = -16;
}
++v3;
while ( !byte_55AB2FA01020[v2] ) // 按选择方向前进直到撞到非0 触边则判定游戏结束
{
if ( v4 == -1 && (v2 & 0xF) == 0 )
return 0LL;
if ( v4 == 1 && v2 % 16 == 15 )
return 0LL;
if ( v4 == 16 && (unsigned int)(v2 - 240) <= 15 )
return 0LL;
if ( v4 == -16 && (unsigned int)(v2 + 15) <= 30 )
return 0LL;
v2 += v4;
}
}
return *(_BYTE *)(v3 + input) == '}';
}打印迷宫
table = '\x00\x00\x00\x00#\x00\x00\x00\x00\x00\x00\x00####\x00\x00\x00##\x00\x00\x00OO\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00OO\x00PP\x00\x00\x00\x00\x00\x00L\x00OO\x00OO\x00PP\x00\x00\x00\x00\x00\x00L\x00OO\x00OO\x00P\x00\x00\x00\x00\x00\x00LL\x00OO\x00\x00\x00\x00P\x00\x00\x00\x00\x00\x00\x00\x00\x00OO\x00\x00\x00\x00P\x00\x00\x00\x00#\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00#\x00\x00\x00\x00\x00\x00\x00\x00\x00MMM\x00\x00\x00#\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00MMM\x00\x00\x00\x00EE\x00\x00\x000\x00M\x00M\x00M\x00\x00\x00\x00E\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00EETTTI\x00M\x00M\x00M\x00\x00\x00\x00E\x00\x00T\x00I\x00M\x00M\x00M\x00\x00\x00\x00E\x00\x00T\x00I\x00M\x00M\x00M!\x00\x00\x00EE'
length = len(table)
j = 0
for i in range(length):
if j == 16:
print("")
j = 0
if table[i] == '\x00':
print("x",end='')
else:
print(table[i],end='')
j += 1得到如下所示的迷宫
x表示数据0的区域
xxxx#xxxxxxx####
xxx##xxxOOxxxxxx
xxxxxxxxOOxPPxxx
xxxLxOOxOOxPPxxx
xxxLxOOxOOxPxxxx
xxLLxOOxxxxPxxxx
xxxxxOOxxxxPxxxx
#xxxxxxxxxxxxxxx
xxxxxxxxxxxx#xxx
xxxxxxMMMxxx#xxx
xxxxxxxMMMxxxxEE
xxx0xMxMxMxxxxEx
xxxxxxxxxxxxxxEE
TTTIxMxMxMxxxxEx
xTxIxMxMxMxxxxEx
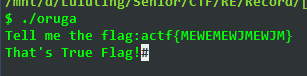
xTxIxMxMxM!xxxEE解迷宫
走法只要保持不撞墙就行

对应操作为 MEWEMEWJMEWJM
套上flag前后缀就成功了
Unity
[BJDCTF2020]BJD hamburger competition
Unity引擎题目
题目内容

老八蜜汁小汉堡
自己配汉堡品尝 有点意思
分析过程
脚本编译方式为Mono
将Assembly-CSharp拖入dnspy分析
找到关键函数
// Token: 0x0600000C RID: 12 RVA: 0x000021C8 File Offset: 0x000003C8
public void Spawn()
{
FruitSpawner component = GameObject.FindWithTag("GameController").GetComponent<FruitSpawner>();
if (component)
{
if (this.audioSources.Length != 0)
{
this.audioSources[Random.Range(0, this.audioSources.Length)].Play();
}
component.Spawn(this.toSpawn);
string name = this.toSpawn.name;
if (name == "汉堡底" && Init.spawnCount == 0)
{
Init.secret += 997;
}
else if (name == "鸭屁股")
{
Init.secret -= 127;
}
else if (name == "胡罗贝")
{
Init.secret *= 3;
}
else if (name == "臭豆腐")
{
Init.secret ^= 18;
}
else if (name == "俘虏")
{
Init.secret += 29;
}
else if (name == "白拆")
{
Init.secret -= 47;
}
else if (name == "美汁汁")
{
Init.secret *= 5;
}
else if (name == "柠檬")
{
Init.secret ^= 87;
}
else if (name == "汉堡顶" && Init.spawnCount == 5)
{
Init.secret ^= 127;
string str = Init.secret.ToString();
if (ButtonSpawnFruit.Sha1(str) == "DD01903921EA24941C26A48F2CEC24E0BB0E8CC7")
{
this.result = "BJDCTF{" + ButtonSpawnFruit.Md5(str) + "}";
Debug.Log(this.result);
}
}
Init.spawnCount++;
Debug.Log(Init.secret);
Debug.Log(Init.spawnCount);
}
}spawnCount为汉堡层数
除开上下两片 还会进行4次操作
最终计算出一个整数值secret
进行Sha1编码后与DD01903921EA24941C26A48F2CEC24E0BB0E8CC7比对
之后计算secret的md5编码
这里注意需要进入函数查看 发现是只取前20位作为flag
解密脚本
用了4重循环来遍历计算哈希
最后计算出secret为0110
因为这里明文比较简单 所以更快可以直接用在线工具解
但那样太浪费这道题了
为了学习 所以还是写出了正常做法
from encodings import utf_8
import hashlib
list = ['鸭屁股','胡罗贝','臭豆腐','俘虏','白拆','美汁汁','柠檬']
#选4种材料
def gen(a):
secret = 997
for choice in a:
if choice == '鸭屁股':
secret -= 127
elif choice == '胡罗贝':
secret *= 3
elif choice == '臭豆腐':
secret ^= 18
elif choice == '俘虏':
secret += 29
elif choice == '白拆':
secret -= 47
elif choice == '美汁汁':
secret *= 5
elif choice == '柠檬':
secret ^= 87
secret ^= 127
return secret
for x1 in range(len(list)):
pick = []
for x2 in range(len(list)):
for x3 in range(len(list)):
for x4 in range(len(list)):
pick.append(list[x1])
pick.append(list[x2])
pick.append(list[x3])
pick.append(list[x4])
res = gen(pick)
res = str(res)
if hashlib.sha1(res.encode('utf-8')).hexdigest().upper() == 'DD01903921EA24941C26A48F2CEC24E0BB0E8CC7':
print(pick)
#print("flag:" + hashlib.md5(res.encode('utf-8')).hexdigest().upper()[:20])
pick = []密码学
RSA
题目给了两个文件
flag.enc
文件内容如图

pub.key
文件内容如下
-----BEGIN PUBLIC KEY----- MDwwDQYJKoZIhvcNAQEBBQADKwAwKAIhAMAzLFxkrkcYL2wch21CM2kQVFpY9+7+ /AvKr1rzQczdAgMBAAE= -----END PUBLIC KEY-----
对这个方向了解不够 直接搜罗一波攻略
BUUCTF–rsa - Hk_Mayfly - 博客园 (cnblogs.com)
CTF中RSA套路 | Err0r (err0rzz.github.io)
解体思路
题目给我们提供了
加密的公钥
通过加密的公钥可以得知
- 大素数乘积N: $N = p * q$
- 加密用的素数E: $密文 = 明文^D mod N$
加密后的密文
想要得到明文需要求E
$明文 = 密文^E mod N$
想要求解密的d
需要拆解两个素数p,q 即找到p,q使得 $n = p * q$
利用p和q计算phi(n)
再利用$E*D = 1\ mod\ phi(n)$
计算出D
即可利用私钥进行解密了
该题的n长度不大,可以直接利用yahu爆破出pq。
通过公钥解析得到n和e
利用线上工具完成RSA公私钥分解 Exponent、Modulus,Rsa公私钥指数、系数(模数)分解–查错网 (chacuo.net)
公钥指数及模数信息:
| key长度: | 256 |
|---|---|
| 模数: | C0332C5C64AE47182F6C1C876D42336910545A58F7EEFEFC0BCAAF5AF341CCDD |
| 指数: | 65537 (0x10001) |
利用yafu分解n获取p,q
将指数作为输入
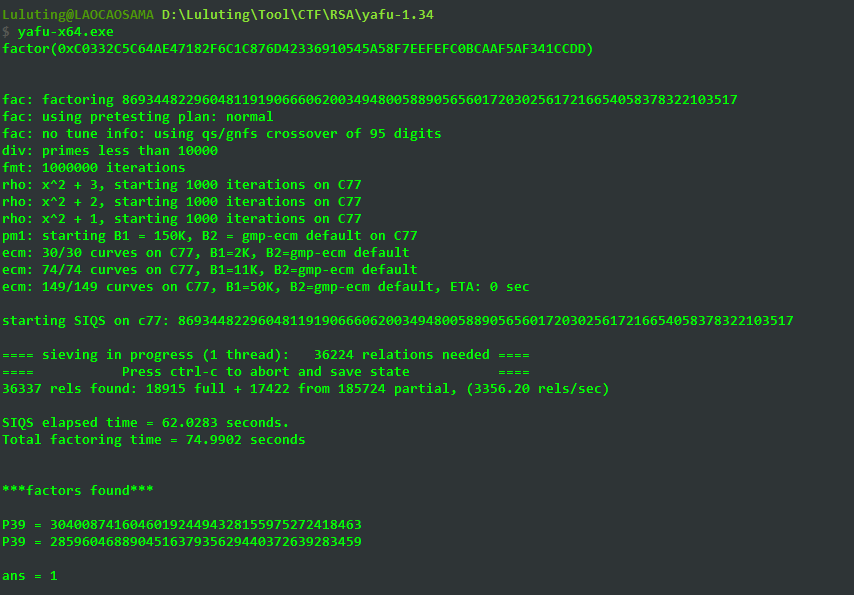
得到
p = 304008741604601924494328155975272418463
q = 285960468890451637935629440372639283459解密脚本
安装gmpy2库
已知e,p,q可以求d
d = gmpy2.invert(e, (p-1)*(q-1))安装rsa库
已知n,e,d,p,q可以求skey
skey = rsa.PrivateKey(n, e, int(d), p, q)所以完全脚本如下
import gmpy2
import rsa
n = 0xC0332C5C64AE47182F6C1C876D42336910545A58F7EEFEFC0BCAAF5AF341CCDD
e = 65537
p = 304008741604601924494328155975272418463
q = 2859604688904516379356294403726392834
phi = (p-1) * (q-1)
d = gmpy2.invert(e, phi)
skey = rsa.PrivateKey(n, e, int(d), p, q)
with open('.\\RSA\\flag.enc','rb+') as f:
text = f.read()
print(rsa.decrypt(text, skey))[SUCTF2019]SignIn
主要逻辑
__int64 __fastcall main(int a1, char **a2, char **a3)
{
char v4[16]; // [rsp+0h] [rbp-4A0h] BYREF
char v5[16]; // [rsp+10h] [rbp-490h] BYREF
char v6[16]; // [rsp+20h] [rbp-480h] BYREF
char v7[16]; // [rsp+30h] [rbp-470h] BYREF
char v8[112]; // [rsp+40h] [rbp-460h] BYREF
char v9[1000]; // [rsp+B0h] [rbp-3F0h] BYREF
unsigned __int64 v10; // [rsp+498h] [rbp-8h]
v10 = __readfsqword(0x28u);
puts("[sign in]");
printf("[input your flag]: ");
__isoc99_scanf("%99s", v8);
sub_96A(v8, v9);
__gmpz_init_set_str(v7, "ad939ff59f6e70bcbfad406f2494993757eee98b91bc244184a377520d06fc35", 16LL);
__gmpz_init_set_str(v6, v9, 16LL);
__gmpz_init_set_str(v4, "103461035900816914121390101299049044413950405173712170434161686539878160984549", 10LL);
__gmpz_init_set_str(v5, "65537", 10LL);
__gmpz_powm(v6, v6, v5, v4);
if ( (unsigned int)__gmpz_cmp(v6, v7) )
puts("GG!");
else
puts("TTTTTTTTTTql!");
return 0LL;
}一开始看sub_96A有点卡壳
size_t __fastcall sub_96A(const char *a1, __int64 a2)
{
size_t result; // rax
int v3; // [rsp+18h] [rbp-18h]
int i; // [rsp+1Ch] [rbp-14h]
v3 = 0;
for ( i = 0; ; i += 2 )
{
result = strlen(a1);
if ( v3 >= result )
break;
*(_BYTE *)(a2 + i) = byte_202010[a1[v3] >> 4];
*(_BYTE *)(a2 + i + 1LL) = byte_202010[a1[v3++] & 0xF];
}
return result;
}看着就感觉这个函数是不可逆的,这真的能做嘛?
这里>>4 和 &0xF操作
前面是取高4位 后面是取低4位
1001.1111.1101.1001 >> 4 = 0000.1001.1111.1101
0000.1001.1111.1101 & 0x0F = 1101 (or 0000.0000.0000.1101 to be more explicit)然后是下面用了gmpz前缀的一系列API也没整明白
搜了一下是高精度数学计算库
趁着周五组会看了半天也没看出个所以然
于是看了一下攻略,才意识到是RSA。
瞬间这几个长字符串和数字都意识到是啥了 焯!
再看逻辑
puts("[sign in]");
printf("[input your flag]: ");
__isoc99_scanf("%99s", input);
sub_96A(input, buffer);
__gmpz_init_set_str(C, "ad939ff59f6e70bcbfad406f2494993757eee98b91bc244184a377520d06fc35", 16LL);
__gmpz_init_set_str(M, buffer, 16LL);
__gmpz_init_set_str(mod, "103461035900816914121390101299049044413950405173712170434161686539878160984549", 10LL);
__gmpz_init_set_str(exp, "65537", 10LL);
__gmpz_powm(M, M, exp, mod);
if ( (unsigned int)__gmpz_cmp(M, C) )
puts("GG!");
else
puts("TTTTTTTTTTql!");sub_96A可以看作是对输入进行一个处理形成明文
RSA的架构就有了
C = 'ad939ff59f6e70bcbfad406f2494993757eee98b91bc244184a377520d06fc35'
N = 103461035900816914121390101299049044413950405173712170434161686539878160984549
e = 65537通过Yafu拆解大素数
$ yafu-x64.exe
factor(103461035900816914121390101299049044413950405173712170434161686539878160984549)
fac: factoring 103461035900816914121390101299049044413950405173712170434161686539878160984549
fac: using pretesting plan: normal
fac: no tune info: using qs/gnfs crossover of 95 digits
div: primes less than 10000
fmt: 1000000 iterations
rho: x^2 + 3, starting 1000 iterations on C78
rho: x^2 + 2, starting 1000 iterations on C78
rho: x^2 + 1, starting 1000 iterations on C78
pm1: starting B1 = 150K, B2 = gmp-ecm default on C78
ecm: 30/30 curves on C78, B1=2K, B2=gmp-ecm default
ecm: 74/74 curves on C78, B1=11K, B2=gmp-ecm default
ecm: 161/161 curves on C78, B1=50K, B2=gmp-ecm default, ETA: 0 sec
starting SIQS on c78: 103461035900816914121390101299049044413950405173712170434161686539878160984549
==== sieving in progress (1 thread): 36224 relations needed ====
==== Press ctrl-c to abort and save state ====
36257 rels found: 18839 full + 17418 from 185433 partial, (3381.62 rels/sec)
SIQS elapsed time = 61.4377 seconds.
Total factoring time = 75.1933 seconds
***factors found***
P39 = 366669102002966856876605669837014229419
P39 = 282164587459512124844245113950593348271
ans = 1 得
p= 366669102002966856876605669837014229419
q = 282164587459512124844245113950593348271解密脚本
这里将整数转换成字符串遇到点问题
可以记录学习学习
import gmpy2
import binascii
p = 366669102002966856876605669837014229419
q = 282164587459512124844245113950593348271
N = 103461035900816914121390101299049044413950405173712170434161686539878160984549
c = 0xad939ff59f6e70bcbfad406f2494993757eee98b91bc244184a377520d06fc35
e = 65537
d = gmpy2.invert(e,(p-1)*(q-1))
m = gmpy2.powmod(c,d,p*q)
temp = bytes(hex(m)[2:],'utf-8')
tem = binascii.unhexlify(temp)
print(tem)异或
配合初始值+自身与自身其他位异或
解法:按原顺序操作顺序复原
异或操作用到了中间值
解法:逆向异或逐步恢复
[FlareOn4]IgniteMe(按原顺序复原)
分析过程
拿到题目函数调用方式挺奇怪
不过不影响判断逻辑
void __noreturn start()
{
DWORD NumberOfBytesWritten; // [esp+0h] [ebp-4h] BYREF
NumberOfBytesWritten = 0;
hScanf = GetStdHandle(0xFFFFFFF6);
hPrintf = GetStdHandle(0xFFFFFFF5);
WriteFile(hPrintf, aG1v3M3T3hFl4g, 0x13u, &NumberOfBytesWritten, 0);
sub_4010F0(); // 获取输入并将输入放入全局变量input
if ( sub_401050(NumberOfBytesWritten) ) // 主要验证逻辑
WriteFile(hPrintf, aG00dJ0b, 0xAu, &NumberOfBytesWritten, 0);
else
WriteFile(hPrintf, aN0tT00H0tRWe7r, 0x24u, &NumberOfBytesWritten, 0);
ExitProcess(0);
}进入sub_401050看
int sub_401050()
{
int length; // [esp+0h] [ebp-Ch]
int i; // [esp+4h] [ebp-8h]
unsigned int j; // [esp+4h] [ebp-8h]
char v4; // [esp+Bh] [ebp-1h]
length = sub_401020((int)input); // 获取长度
v4 = sub_401000(); // 计算固定值 v4 = 04
for ( i = length - 1; i >= 0; --i )
{
byte_403180[i] = v4 ^ input[i];
v4 = input[i];
}
for ( j = 0; j < 39; ++j ) // 长度39
{
if ( byte_403180[j] != (unsigned __int8)byte_403000[j] )
return 0;
}
return 1;
}sub_401000计算一个固定值__int16 sub_401000() { return (unsigned __int16)__ROL4__(0x80070000, 4) >> 1; }0x80070000循环左移4位之后为0x00700008算数右移之后为
0x00700004最后返回16位结果为04- 从最后的判断可知长度为39,处理后的数组位于
byte_403000
之后的操作是
将输入从最后一位开始
当前位与上一位异或后存入值
第一次处理和初始值04异或
计算顺序为
byte_403180[28] = input[28] ^ 04 byte_403180[27] = input[27] ^ input[28] .. byte_403180[0] = input[0] ^ input[1]- 从最后的判断可知长度为39,处理后的数组位于
所以我们的解密算法需要从最后一位开始还原 按原来的顺序恢复input
解密算法
byte_403000 = '\r&IE*\x17xD+l]^E\x12/\x17+DonV\t_EGs&\n\r\x13\x17HB\x01@M\x0c\x02i'
v4 = 4
input = [''] * 39
for i in range(38,-1,-1):
input[i] = chr(ord(byte_403000[i]) ^ v4)
v4 = ord(input[i])
input = ''.join([c for c in input])
print(input)[GWCTF 2019]xxor
关键逻辑
main
__int64 __fastcall main(int a1, char **a2, char **a3)
{
int i; // [rsp+8h] [rbp-68h]
int j; // [rsp+Ch] [rbp-64h]
__int64 v6[6]; // [rsp+10h] [rbp-60h] BYREF
__int64 v7[6]; // [rsp+40h] [rbp-30h] BYREF
v7[5] = __readfsqword(0x28u);
puts("Let us play a game?");
puts("you have six chances to input");
puts("Come on!");
v6[0] = 0LL;
v6[1] = 0LL;
v6[2] = 0LL;
v6[3] = 0LL;
v6[4] = 0LL;
for ( i = 0; i <= 5; ++i )
{
printf("%s", "input: ");
a2 = (char **)((char *)v6 + 4 * i); // 6个DWORD
__isoc99_scanf("%d", a2);
}
v7[0] = 0LL;
v7[1] = 0LL;
v7[2] = 0LL;
v7[3] = 0LL;
v7[4] = 0LL;
for ( j = 0; j <= 2; ++j )
{
dword_601078 = v6[j]; // 输入1
dword_60107C = HIDWORD(v6[j]); // 输入2
a2 = (char **)dword_601060;
sub_400686((unsigned int *)&dword_601078, dword_601060);// 操作dword_601078 dword_60107C
LODWORD(v7[j]) = dword_601078;
HIDWORD(v7[j]) = dword_60107C;
}
if ( (unsigned int)sub_400770(v7, a2) != 1 ) // 验证v7数组
{
puts("NO NO NO~ ");
exit(0);
}
puts("Congratulation!\n");
puts("You seccess half\n");
puts("Do not forget to change input to hex and combine~\n");
puts("ByeBye");
return 0LL;
}sub_400686
sub_400770
__int64 __fastcall sub_400770(_DWORD *a1)
{
__int64 result; // rax
if ( a1[2] - a1[3] == 2225223423LL
&& a1[3] + a1[4] == 4201428739LL
&& a1[2] - a1[4] == 1121399208LL
&& *a1 == -548868226
&& a1[5] == -2064448480
&& a1[1] == 550153460 )
{
puts("good!");
result = 1LL;
}
else
{
puts("Wrong!");
result = 0LL;
}
return result;
}分析过程
从sub_400770入手得到v7数组
__int64 __fastcall sub_400770(_DWORD *a1)
{
__int64 result; // rax
if ( a1[2] - a1[3] == 0x84A236FFLL // 三元一次方程
&& a1[3] + a1[4] == 0xFA6CB703LL
&& a1[2] - a1[4] == 0x42D731A8LL
&& *a1 == 0xDF48EF7E
&& a1[5] == 0x84F30420
&& a1[1] == 0x20CAACF4 )
{
puts("good!");
result = 1LL;
}
else
{
puts("Wrong!");
result = 0LL;
}
return result;
}这里要解一个三元一次方程

最后得v7数组如下
v7 = [0] * 6
v7[0] = 0xDF48EF7E
v7[1] = 0x20CAACF4
v7[5] = 0x84F30420
v7[2] = 0xe0f30fd5
v7[3] = 0x5c50d8d6
v7[4] = 0x9e1bde2d接着从sub_400686逆推出输入即可
解密脚本
因为都是在用32位寄存器操作,用python就显得不太方便。
直接copy伪代码跑起来
#include <stdio.h>
#include <Windows.h>
__int64 __fastcall sub_400686(unsigned int* input, int* dword_601060)
{
__int64 result; // rax
unsigned int firstDword; // [rsp+1Ch] [rbp-24h]
unsigned int secondDword; // [rsp+20h] [rbp-20h]
int v5; // [rsp+24h] [rbp-1Ch]
unsigned int i; // [rsp+28h] [rbp-18h]
firstDword = *input; // input1
secondDword = input[1]; // //input2
v5 = 0x458BCD42 * 64;
for (i = 0; i <= 63; i++)
{
secondDword -= (firstDword + v5 + 20) ^ ((firstDword << 6) + dword_601060[2]) ^ ((firstDword >> 9) + dword_601060[3]) ^ 0x10;
firstDword -= (secondDword + v5 + 11) ^ ((secondDword << 6) + *dword_601060) ^ ((secondDword >> 9) + dword_601060[1]) ^ 0x20;
v5 -= 0x458BCD42;
}
*input = firstDword;
result = secondDword;
input[1] = secondDword;
return result;
}
int main() {
int dword_601060[4] = { 2,2,3,4 };
int v7[6] = { 0 };
v7[0] = 0xDF48EF7E;
v7[1] = 0x20CAACF4;
v7[5] = 0x84F30420;
v7[2] = 0xe0f30fd5;
v7[3] = 0x5c50d8d6;
v7[4] = 0x9e1bde2d;
for (int j = 0; j <= 4; j += 2)
{
int dword_601078[2] = { 0 };
dword_601078[0] = v7[j]; // 输入1
dword_601078[1] = v7[j + 1]; // 输入2
sub_400686((unsigned int*)&dword_601078, dword_601060);// 操作dword_601078 dword_60107C
v7[j] = dword_601078[0];
v7[j + 1] = dword_601078[1];
}
for (int i = 0; i < 6; i++) {
printf("%c%c%c", *((char*)&v7[i] + 2), *((char*)&v7[i] + 1), *((char*)&v7[i]));
}
return 0;
}base64换表
[ACTF新生赛2020]usualCrypt(好评)
base64编码是固定的字符处理
于是将按表中的差异直接替换即可
flag = base64.b64decode(flag.translate(str.maketrans(string_trans,string_bak)))
逻辑分析
main函数
printf(aGiveMeYourFlag);
scanf("%s", input);
v5[0] = 0;
v5[1] = 0;
v5[2] = 0;
v6 = 0;
v7 = 0;
sub_401080(input, strlen(input), v5);
v3 = 0;
while ( *((_BYTE *)v5 + v3) == byte_40E0E4[v3] )
{
if ( ++v3 > strlen((const char *)v5) )
goto LABEL_6;
}
printf(aError);录入输出经过函数sub_401080处理得v5
v5与byte_40E0E4进行比对
sub_401080函数内容如下
可以看出是base64编码
int __cdecl sub_401080(int input, int length, int output)
{
int v3; // edi
int v4; // esi
int v5; // edx
int v6; // eax
int v7; // ecx
int v8; // esi
int v9; // esi
int v10; // esi
int v11; // esi
_BYTE *v12; // ecx
int v13; // esi
int lengtha; // [esp+18h] [ebp+8h]
v3 = 0;
v4 = 0;
sub_401000(); // 对base64密码表进行处理
v5 = length % 3;
v6 = input;
v7 = length - length % 3;
lengtha = length % 3;
if ( v7 > 0 )
{
do
{
LOBYTE(v5) = *(_BYTE *)(input + v3);
v3 += 3;
v8 = v4 + 1;
*(_BYTE *)(v8 + output - 1) = byte_40E0A0[(v5 >> 2) & 0x3F];
*(_BYTE *)(++v8 + output - 1) = byte_40E0A0[16 * (*(_BYTE *)(input + v3 - 3) & 3)
+ (((int)*(unsigned __int8 *)(input + v3 - 2) >> 4) & 0xF)];
*(_BYTE *)(++v8 + output - 1) = byte_40E0A0[4 * (*(_BYTE *)(input + v3 - 2) & 0xF)
+ (((int)*(unsigned __int8 *)(input + v3 - 1) >> 6) & 3)];
v5 = *(_BYTE *)(input + v3 - 1) & 0x3F;
v4 = v8 + 1;
*(_BYTE *)(v4 + output - 1) = byte_40E0A0[v5];
}
while ( v3 < v7 );
v5 = lengtha;
}
if ( v5 == 1 )
{
LOBYTE(v7) = *(_BYTE *)(v3 + input);
v9 = v4 + 1;
*(_BYTE *)(v9 + output - 1) = byte_40E0A0[(v7 >> 2) & 0x3F];
v10 = v9 + 1;
*(_BYTE *)(v10 + output - 1) = byte_40E0A0[16 * (*(_BYTE *)(v3 + input) & 3)];
*(_BYTE *)(v10 + output) = 61;
LABEL_8:
v13 = v10 + 1;
*(_BYTE *)(v13 + output) = 61;
v4 = v13 + 1;
goto LABEL_9;
}
if ( v5 == 2 )
{
v11 = v4 + 1;
*(_BYTE *)(v11 + output - 1) = byte_40E0A0[((int)*(unsigned __int8 *)(v3 + input) >> 2) & 0x3F];
v12 = (_BYTE *)(v3 + input + 1);
LOBYTE(v6) = *v12;
v10 = v11 + 1;
*(_BYTE *)(v10 + output - 1) = byte_40E0A0[16 * (*(_BYTE *)(v3 + input) & 3) + ((v6 >> 4) & 0xF)];
*(_BYTE *)(v10 + output) = byte_40E0A0[4 * (*v12 & 0xF)];
goto LABEL_8;
}
LABEL_9:
*(_BYTE *)(v4 + output) = 0;
return sub_401030(output); // 对base64编码的结果进行大小写互换
}可以看到sub_401000里对base64密码表byte_40E0A0进行了处理
int sub_401000()
{
int result; // eax
char v1; // cl
for ( result = 6; result < 15; ++result )
{
v1 = byte_40E0AA[result];
byte_40E0AA[result] = byte_40E0A0[result];
byte_40E0A0[result] = v1;
}
return result;
}最后返回结果前sub_401030对base64编码的结果进行大小写互换
int __cdecl sub_401030(const char *a1)
{
__int64 v1; // rax
char v2; // al
v1 = 0i64;
if ( strlen(a1) )
{
do
{
v2 = a1[HIDWORD(v1)];
if ( v2 < 'a' || v2 > 'z' )
{
if ( v2 < 'A' || v2 > 'Z' )
goto LABEL_9;
LOBYTE(v1) = v2 + 32;
}
else
{
LOBYTE(v1) = v2 - 32;
}
a1[HIDWORD(v1)] = v1;
LABEL_9:
LODWORD(v1) = 0;
++HIDWORD(v1);
}
while ( HIDWORD(v1) < strlen(a1) );
}
return v1;
}解密思路
将加密后的结果进行大小写互换得到
byte_40E0E4将base64密码表按
usb_401000处理得到string_trans用处理后的密码表
string_trans将byte_40E0E4解码得Flag
解密脚本
这次学习了字符串替换
import base64
import string
def sub_401030(a):
result = ''
for c in a:
if c >= 'a' and c <= 'z':
result += chr(ord(c) - ord('a') + ord('A'))
elif c >= 'A' and c <= 'Z':
result += chr(ord(c) - ord('A') + ord('a'))
else:
result += c
return result
def sub_401000(a):
temp = list(a)
for i in range(6,15):
tempv = temp[i + 0xA]
temp[i + 0xA] = temp[i]
temp[i] = tempv
res = ''.join([c for c in temp])
return res
string_bak = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
string_trans = sub_401000(string_bak)
byte_40E0E4 = 'zMXHz3TIgnxLxJhFAdtZn2fFk3lYCrtPC2l9'
byte_40E0E4 = sub_401030(byte_40E0E4)
flag = base64.b64decode(byte_40E0E4.translate(str.maketrans(string_trans,string_bak)))
print(flag)[WUSTCTF2020]level3
打开题目发现是个base64翻译机
分析过程
主函数逻辑如下
int __cdecl main(int argc, const char **argv, const char **envp)
{
char *v3; // rax
char v5; // [rsp+Fh] [rbp-41h]
char v6[56]; // [rsp+10h] [rbp-40h] BYREF
unsigned __int64 v7; // [rsp+48h] [rbp-8h]
v7 = __readfsqword(0x28u);
printf("Try my base64 program?.....\n>");
__isoc99_scanf("%20s", v6);
v5 = time(0LL);
srand(v5);
if ( (rand() & 1) != 0 )
{
v3 = base64_encode(v6);
puts(v3);
puts("Is there something wrong?");
}
else
{
puts("Sorry I think it's not prepared yet....");
puts("And I get a strange string from my program which is different from the standard base64:");
puts("d2G0ZjLwHjS7DmOzZAY0X2lzX3CoZV9zdNOydO9vZl9yZXZlcnGlfD==");
puts("What's wrong??");
}
return 0;
}发现题目给出了待翻译字符串
d2G0ZjLwHjS7DmOzZAY0X2lzX3CoZV9zdNOydO9vZl9yZXZlcnGlfD==
但这表和标准的表不一样
于是看表的交叉引用
发现O_OLookAtYou函数对表进行了局部换位操作
__int64 O_OLookAtYou()
{
__int64 result; // rax
char v1; // [rsp+1h] [rbp-5h]
int i; // [rsp+2h] [rbp-4h]
for ( i = 0; i <= 9; ++i )
{
v1 = base64_table[i];
base64_table[i] = base64_table[19 - i];
result = 19 - i;
base64_table[result] = v1;
}
return result;
}于是将表修改之后将题目提供的字符串解码即可获得flag
解密脚本
import base64
table_bak = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'
table = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'
table = list(table)
for i in range(10):
temp = table[i]
table[i] = table[19 - i]
table[19 - i] = temp
table = ''.join([c for c in table])
flag = 'd2G0ZjLwHjS7DmOzZAY0X2lzX3CoZV9zdNOydO9vZl9yZXZlcnGlfD=='
print(base64.b64decode(flag.translate(str.maketrans(table,table_bak))))常用库方法
字符处理
binascii
hexlify:字符串转hex
unhexlify:hex转字符串
base64
b64decode
密码学
gmpy2
d = gmpy2.invert(e, phi)
m = gmpy2.powmod(c, d, p*q)
rsa
skey = rsa.PrivateKey(n, e, int(d), p, q)
import gmpy2
import rsa
d = gmpy2.invert(e,(p-1)*(q-1))
m = gmpy2.powmod(c,d,p*q)
n = 0xC0332C5C64AE47182F6C1C876D42336910545A58F7EEFEFC0BCAAF5AF341CCDD
e = 65537
p = 304008741604601924494328155975272418463
q = 2859604688904516379356294403726392834
phi = (p-1) * (q-1)
d = gmpy2.invert(e, phi)
skey = rsa.PrivateKey(n, e, int(d), p, q)
with open('.\\RSA\\flag.enc','rb+') as f:
text = f.read()
print(rsa.decrypt(text, skey))hashlib
md5/sha1等
编码后需要用hexdigest()方法得字符串

