0x01 前言
模糊测试是一种用于快速检测安全漏洞的安全测试技术,实质上是通过向程序提供非预期的输入并监控输出是否出现异常来判断并挖掘软件或服务中的漏洞。
近年来模糊测试经历了快速发展,逐渐成为一种重要的漏洞扫描挖掘技术,因此我们学习模糊测试技术需要了解其技术的具体工作流程以及发展趋势,进行总结与分析归纳,为之后的学习提供参考。
模糊测试通常包含五大环节:预处理、输入数据构造、输入选择、评估和结果分析,其中每个环节结合相应的研究进行分析和总结。
不同领域中使用模糊测试技术时会有很大的差异,因为在不同的应用场景下,模糊测试的会有不一样的需求。同时随着反模糊测试技术也在发展,模糊测试技术平台更需要加强,我们要明白模糊测试下一步应该如何发展。
0x02 技术背景
近年来利用漏洞实施得攻击行为层出不穷,网络在给人们带来便捷的同时,人们对网络日渐产生依赖性,安全隐患也在增加以及其造成的后果也越来越不可估量。2010年,“震网”病毒在全球各地爆发,利用当时Windows系统中的多个未被公开的漏洞、伪造数字签名是其主要手段,从而入侵到SCADA设备使其瘫痪0。除了感染全球各地的四万五千余台设备,更是感染了伊朗核电站中核燃料浓缩过程的SCADA设备,造成伊朗核项目瘫痪长达两年;2017年,Wannacry勒索病毒攻击了全球各地近百余个国家,黑客使用由美国国家安全局开发出的漏洞攻击工具,利用MS17-010漏洞感染大量个人计算机,计算机中许多关键数据被黑客锁定加密。
这类攻击的发生一般都是由个系统中的安全漏洞导致。尽管网络上已经有许多公开的漏洞收录网站,但是依旧有许多潜藏的、未被发现的安全漏洞存在着。因此如何减少漏洞,保证系统或应用服务的质量,成为安全领域里一项至关重要的工作。通常用于挖掘安全漏洞的方法分为三种:白盒测试、黑盒测试以及灰盒测试。白盒测试主要方法是源代码审计。因为可以获取所有源代码,所以能够覆盖程序的所有运行路径,但是复杂性高;黑盒测试是一种不需要知道检测目标内部细节,而直接进行输入测试的一种方法,操作简单,覆盖路径一般,且实验过程中会产生大量无效测试用例;灰盒测试介于白盒测试与黑盒测试之间,即通过一些自动化的二进制审核工具如IDA、Ghidra等进行二进制审核,复杂性也较高,通常要花费大量时间。
而模糊测试就属于黑盒测试里的一种具体技术。这项技术是在1988年由威斯康星大学Barton Miller教授首次提出,通过Fuzz生成器用于测试UNIX程序的健壮性,使用随机数据输入来测试直到让程序崩溃。直至今天模糊测试已经成为漏洞扫描与检测的一种重要方法。
0x03 发展历程
模糊测试最早可追溯到1989年,威斯康辛大学的B.P.Miller开发了一个模糊测试工具并命名为Fuzz,用来对UNIX系统上的软件进行安全性测试。
最近网络出现的与OpenSSL相关的HeatBleed漏洞的发现工具就是在PROTOS的基础上发展起来的。PROTOS是模糊测试技术发展过程中的一个重要的里程碑。
2002年,Immunitysec公司的Dave Aitel开发了一款通用协议测试框架工具SPIKE。SPIKE主要用于测试基于网络的应用程序,采用了一种基于块的方法,能够有效地对包含变量和相应变量长度的数据块进行测试,同时,SPIKE可以从大量的数据样例中自动学习目标软件的数据规约。作为第一个可以实现自定制的模糊测试器框架,SPIKE的发布是模糊测试历史上一个最重要的里程碑。
2004年,IOACTIVE发布了著名的跨平台模糊测试框架Peach。它采用Python语言编写。Peach几乎可以对所有常见的对象进行模糊测试,例如文件结构、COM对象、网络协议、API接口等。使用Peach时,其主要工作就是定义一个XML文件来引导测试过程。Peach是一个灵活的模糊测试框架,最大程度地实现了代码重用。
2008年,为了对输入数据高度结构化的目标进行模糊检测,诞生了jsfunfuzz。该方法根据语法模型生成随机的但语法正确的JavaScript代码,这种基于语法生成输入的思想,成为之后对输入数据高度结构化目标进行模糊测试的重要指导思想。
2011年之后,众多学者将遗传算法、启发式算法等用于生成模糊测试用例,大大提高了测试用例的生成效率。同时,多维模糊测试研究的兴起也弥补了传统模糊测试只能挖掘单点触发漏洞的不足[2]。
上面列举了模糊测试发展历程中比较重要的时间点,目前来看模糊测试技术应用最多的领域是程序分析领域,特别是在漏洞扫描挖掘方面,模糊测试技术应用非常多。
0x04 工作流程
一次完整的模糊测试流程可以通过如下图所示,可分为5个步骤:预处理、输入构造、输入选择、评估、结果分析。预处理是测试开始前的准备工作,而结果分析是测试结束后的分析工作,实际上模糊测试执行中为输入构造、输入选择、评估三个子环节。
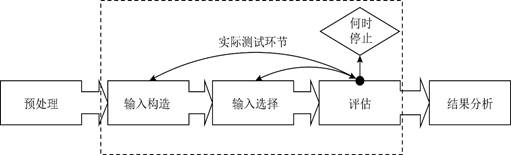
首先,预处理的工作是根据分析目标制定测试的策略,为了时刻关注测试目标在测试过程中的运行状况,我们需要做一些预先的准备:通常是依赖程序分析技术如符号执行、插桩以及污点分析等等。
预处理之后需要进行输入构造、输入选择、评估三个环节。
输入构造是指生成大量输入数据,这一环节通常通过种子来随机生成。通过输入构造得到大量数据后,接着通过输入选择环节来筛选数据,主要目的是尽可能提前过滤掉无效的输入数据,提升输入数据的有效性,从而提升整体模糊测试的效率。接着评估部分的工作是:制定一个能够真实反馈模糊测试执行结果的评估指标,设计一个合适的实验能够确切反应模糊测试的性能。通常需要选择一个模糊测试方法去测试相同的对象用作对比、测试重复次数以及时间等等。
模糊测试的结果无法直接使用,我们需要在结果分析环节对结果进行分析。分析通常包括对测试结果的去重、复现,对测试结果进行威胁性评估等工作,经过这些操作最终来判断是否发现漏洞。
0x05 技术细节
I.预处理环节
预处理环节中我们需要为监测程序运行状态做准备,常用的技术手段包括:插桩、符号执行以及污点分析
(1)插桩
插桩技术需要向测试目标的代码中加入预设的代码从而获取程序信息,而这种信息获取方法大体上分为两种:静态插桩和动态插桩。静态插桩需要依赖程序的源代码,在程序源码或者编译环节中进行插桩,其优点是处理速度快、节约时间成本,但需要依赖程序源码;相对应的动态插桩是在程序运行过程中对内存中的二进制代码段进行动态插桩,这种手段能够获取程序运行过程中的信息,但是相对资源开销很大。
总体上来说插桩技术为监控程序状态带来很大的帮助,但是资源开销会增大许多。
(2)符号执行
符号执行技术可以通过分析程序来得到让特定代码区域执行的输入。顾名思义,使用符号执行分析一个程序时,该程序会使用符号值作为输入,而非一般执行程序时使用的具体值。在达到目标代码时,分析器可以得到相应的路径约束,然后通过约束求解器来得到可以触发目标代码的具体值[4]。即是构建一个程序的执行路径,推断目标在不同输入上的行为,让测试覆盖率显著提升,探寻更多可能存在漏洞的区域。这种技术也分为静态符号执行和动态符号执行。静态符号不真实执行程序,解析程序通过符号值模拟执行,执行在遇到循环和递归代码时会陷入到路径爆炸的问题中,所以目前使用较多的是动态符号执行的方法,通过实际运行程序以及符号化执行程序,结合真实执行和传统符号执行的优点,在程序执行过程中同时进行符号执行,能够缓解静态符号执行的问题。
(3)污点分析
污点分析技术是将不受信任来源的输入数据视为污染数据,然后监视程序的执行情况以跟踪污染数据传播,并检查污染数据何时被使用[5]。污点分析可以抽象成一个三元组<sources,sinks,sanitizers>的形式,其中,sourcse代表污点源,代表直接引入不受信任的数据或者机密数据到系统中;sink代表污点汇聚点,表示直接产生安全敏感操作(违反数据完整性)或者泄露隐私数据到外界(违反数据保密性);sanitizer代表无害处理,表示通过数据加密或者移除危害操作等手段使数据传播不再对软件系统的信息安全产生危害。污点分析就是分析程序中由污点源引入的数据是否能够不经无害处理,而直接传播到污点汇聚点,如果不能,说明系统是信息流安全的;否则,说明系统产生了隐私数据泄露或危险数据操作等安全问题[6]。
污点分析也分为静态污点分析和动态污点分析。静态污点分析不实际执行程序,通过静态解析目标程序,依赖程序数据流图和数据关系进行污点分析;而动态污点分析是实际执行目标程序,利用动态执行信息进行污点分析,这种方式的可信度更高,但相对的也就会消耗更多的资源。
II.输入构造环节
输入构造环节需要构造出可以被检测目标执行的输入数据,具体面临的问题是如何在短时间内生成大量尽可能满足语法语义的输入来进行测试。
通常方法是获得一个数据Data,然后数据Data按照一定的策略进行若干次变异,获得大量的新数据DataII,将DataII输入到被测目标中进行测试,在这个过程中数据Data就被称为种子,DataII是模糊测试中实际输入的数据。通过这种方式,只要能保证种子的有效性以及通过合理的变异方式,我们就能在短时间内获得大量的高质量测试数据以供输入。
III.输入选择环节
输入选择的目的主要是在开始输入之前,对测试数据中的无效数据提前进行过滤,来达到节省测试执行时间的目的。这个环节面临的主要问题是在不进行测试的情况下,如何判断一组输入数据是否是有效的。这是一个与模式识别相关的问题,目前通常会使用机器学习的技术来解决。总体来说,这一步的主要思想就是筛选输入数据,提升模糊测试的效率。但是这个环节并不是必须的,需要根据具体的需求和资源情况来进行衡量,确保增加输入选择环节后是否能够提升模糊测试整体的效率,否则增加该环节将会毫无意义且冗余。
IV.评估环节
评估环节用于评估模糊测试的执行结果,该环节面临的问题是如何选取一个合适的评估指标,从而帮助模糊测试进一步的策略以及该模糊测试检测漏洞的能力。
目前阶段研究主要重视的指标是:覆盖率和漏洞暴露平均时间。覆盖率指的是测试对象执行过程中被覆盖到的数目占总数的比例,是软件测试中的一个衡量指标。一般高覆盖率意味着更多的漏洞发现机会。而对于不同场景,覆盖率可能不再是合适的评估项,存在漏洞的代码并不是全部,太过重视覆盖率,可能会让模糊测试工具在不存在漏洞的部分投入过多成本,这种时候代码覆盖率不再是主要指标,而是以暴露漏洞的平均时间来进行评估。这种方式和覆盖率相比,更加重视发现漏洞的能力。暴露漏洞的平均时间能证明模糊测试工具挖掘漏洞的能力,即纵向挖掘能力,而覆盖率能够帮助模糊测试工具发现更多的漏洞,即横向拓展能力,两者需要结合发展综合考虑。
V.结果分析环节
结果分析环节是在模糊测试过程结束后,对模糊测试的输出报告进行分析。这一环节面临的主要问题是安全人员通常要手动分析从模糊测试中得到的输出状态并进行复现,研究其发生的根本原因,根据威胁程度来判断该漏洞是否有意义。这个过程需要安全人员拥有良好的漏洞分析和复现能力。
0x06 发展趋势
模糊测试在漏洞检测上发挥着重要的作用,但这种技术也能为攻击者提供便利,攻击者也可以用这种技术来进行漏洞挖掘并进行恶意利用。因此对抗模糊测试的反模糊测试技术也逐渐被人开始研究,不仅是对防止自身被模糊测试的研究,还是怎么去绕过反模糊测试的研究,都对模糊测试这门技术里非常重要。
目前模糊测试的种类复杂繁多,应用在各个领域,目前模糊测试虽然有许许多多的工具,但是一直都没有一个通用的平台,这也是模糊测试方向的一个重要的挑战。
同时近年来,机器学习技术在其他领域飞速发展,这项技术与模糊测试中各个工作环节相结合的新方法也在不断出现,如何将两者最大限度结合起来发挥两者的优势也是正在着重研究的方向。
0x07 结束语
随着国家推进网络空间安全专业的大力发展,国内模糊测试技术相关的研究正在逐渐多起来。模糊测试诞生时被用于分析程序的可用性,直到今天,它已经是漏洞检测和挖掘领域中不可或缺的技术。
本报告对模糊测试的发展进行概述,对模糊测试技术所涵盖的整体工作流程进行总结,也针对流程中的每一个环节的工作方式进行了介绍和讲解,最终对模糊测试技术目前所遇到的机遇和挑战进行分析。
希望今后模糊测试技术能够进一步发展,在漏洞挖掘领域继续大放光彩。
课题报告选择这个方向主要是为漏洞挖掘学习打知识基础,今后实操之后也许会再继续补充本篇吧。
0x08 参考文献
[1] 蒲石,陈周国,祝世雄.震网病毒分析与防范[J].信息网络安全,2012(02):40-43.
[2] 张雄,李舟军.模糊测试技术研究综述[J].计算机科学,2016,43(05):1-8+26.
[3] 谢肖飞,李晓红,陈翔,孟国柱,刘杨.基于符号执行与模糊测试的混合测试方法[J].软件学报,2019,30(10):3071-3089.DOI:10.13328/j.cnki.jos.005789.
[4] 符号执行技术总结(A Brief Summary of Symbol Execution)- wcventure_wcventure的博客-CSDN博客_符号执行
[5] 黄冬秋,韩毅,杨佳庚,田志宏.基于二进制程序的动态污点分析技术研究综述[J].广州大学学报(自然科学版),2020,19(02):57-68.
[6] 污点分析 - 程序员大本营 (pianshen.com)
[7] 5.1 模糊测试 · CTF All In One (gitbooks.io)
[8] 陈衍铃,王正.模糊测试研究进展[J].计算机应用与软件,2011,28(07):291-293+295.
[9] 任泽众,郑晗,张嘉元,王文杰,冯涛,王鹤,张玉清.模糊测试技术综述[J].计算机研究与发展,2021,58(05):944-963.
[10]李贺,张超,杨鑫,朱俊虎.操作系统内核模糊测试技术综述[J].小型微型计算机系统,2019,40(09):1994-1999.

